Overfitting Challenge
Youtube search... ...Google search
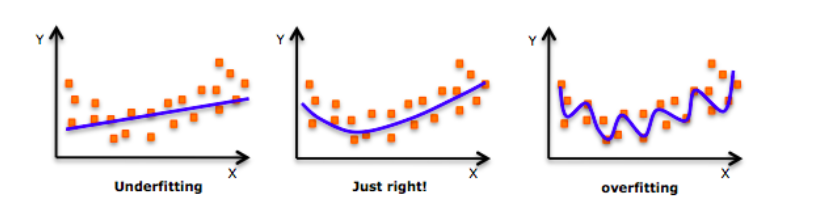
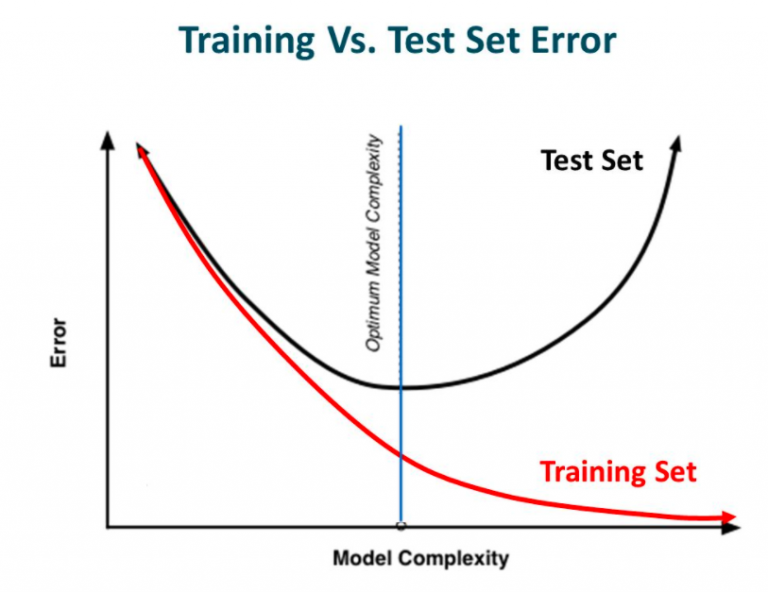
Over-fitting is a problem in machine learning in general, not just in neural networks. The problem is inherent in the way machine learning models are developed: A set of "training data" is used to "train" the model. The goal is to have a model that can then be used on data that hasn't been seen before. Over-fitting refers to the problem of having the model trained to work so well on the training data that it starts to work more poorly on data it hasn't seen before. There are a number of techniques to mitigate or prevent over-fitting. | Deep Learning Course Wiki
Good practices:
- add more data
- use Data Augmentation
- use batch normalization
- use architectures that generalize well
- reduce architecture complexity
- add Regularization
- L2 and L1 Regularization - update the general cost function by adding another term known as the regularization term.
- Dropout - at every iteration, it randomly selects some nodes and temporarily removes the nodes (along with all of their incoming and outgoing connections)
- Data Augmentation
- Early Stopping