Natural Language Processing (NLP)
Speech recognition, speech translation, understanding complete sentences, understanding synonyms of matching words, sentiment analysis, and writing complete grammatically correct sentences and paragraphs.
- Outline of natural language processing | Wikipedia
- Natural Language Processing | Wikipedia
- Grammar Induction | Wikipedia
- The Stanford Natural Language Inference (SNLI) Corpus
- How do I learn Natural Language Processing? | Sanket Gupta
- AI-Powered Search
- Natural Language | Chris Umbel
- NLP News | Sebastian Ruder
- Language services | Cognitive Services | Microsoft Azure
- Text Transfer Learning
Contents
- 1 Pipeline
- 2 Regular Expressions (Regex)
- 3 Tokenization / Sentence Splitting
- 4 Stop Words
- 5 Stemming (Morphological Similarity)
- 6 Part-of-Speech (POS) Tagging
- 7 Chunking
- 8 Chinking
- 9 Named Entity Recognition (NER)
- 10 Neural Coreference
- 11 Hierarchical Classifier
- 12 Lemmatization
- 13 Corpora
- 14 Topic Modeling
- 15 Word Embeddings
- 16 Summarizer
- 17 Ontologies
- 18 Natural Language Inference (NLI) and Recognizing Textual Entailment (RTE)
- 19 Deep Learning Algorithms
- 20 Evaluation Measures - Classification Performance
- 21 Capabilities
Pipeline
- Natural Language Tools:
- Outline of natural language processing | Wikipedia
- CogComp NLP Pipeline | Cognitive Computation Group, led by Prof. Dan Roth

Regular Expressions (Regex)
Search for text patterns, validate emails and URLs, capture information, and use patterns to save development time.

Tokenization / Sentence Splitting

Stop Words
Stemming (Morphological Similarity)
Refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
Part-of-Speech (POS) Tagging
Chunking
Chinking
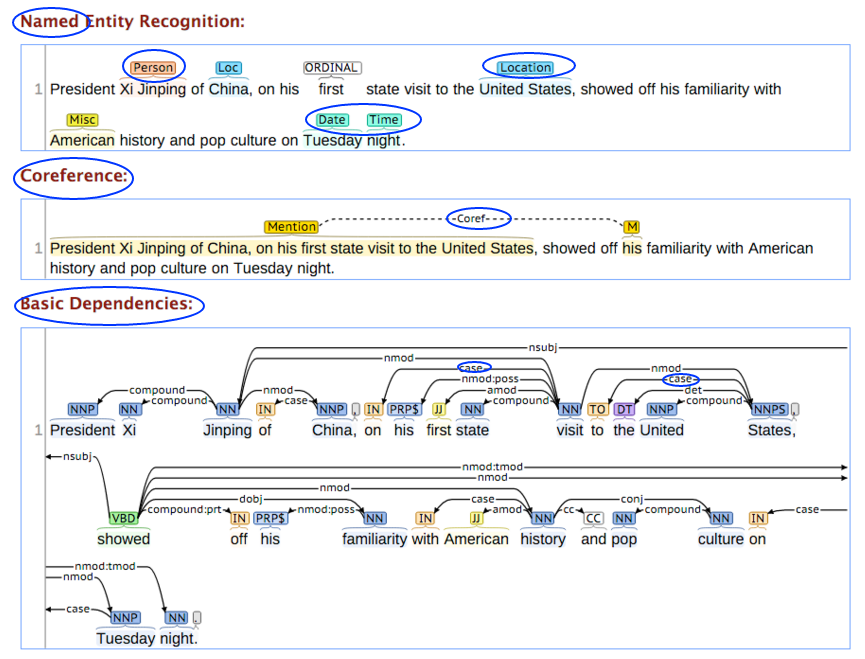
Named Entity Recognition (NER)
(also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Most research on NER systems has been structured as taking an unannotated block of text, and producing an annotated block of text that highlights the names of entities.
Neural Coreference
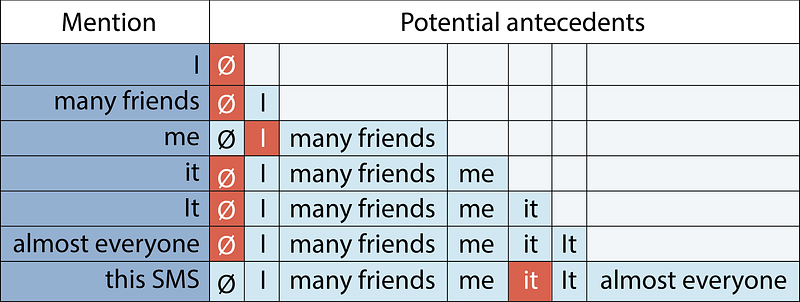
Coreference is the fact that two or more expressions in a text – like pronouns or nouns – link to the same person or thing. It is a classical Natural language processing task, that has seen a revival of interest in the past two years as several research groups applied cutting-edge deep-learning and reinforcement-learning techniques to it. It is also one of the key building blocks to building conversational Artificial intelligences.
Hierarchical Classifier
- A Survey of Hierarchical Classification Across Different Application Domains | Carlos N. Silla Jr. and Alex A. Freitas
- Hierarchical Classification – a useful approach for predicting thousands of possible categories | Pedro Chaves - KDnuggets
Classification approaches:
- Flat - there is no inherent hierarchy between the possible categories the data can belong to (or we chose to ignore it). Train either a single classifier to predict all of the available classes or one classifier per category (1 vs All)
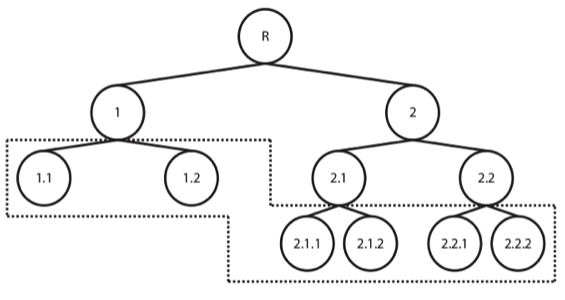
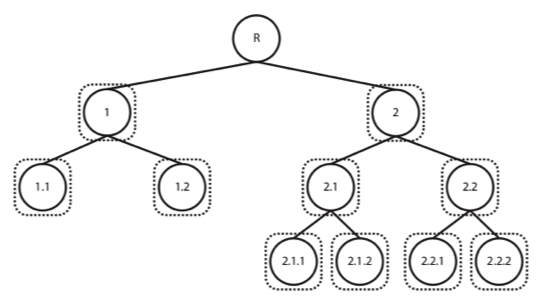
- Hierarchically - organizing the classes, creating a tree or DAG (Directed Acyclic Graph) of categories, exploiting the information on relationships among them. Although there are different types of hierarchical classification approaches, the difference between both modes of reasoning and analysing are particularly easy to understand in these illustrations, taken from a great review on the subject by Silla and Freitas (2011). Taking a top-down approach, training a classifier per level (or node) of the tree (again, although this is not the only hierarchical approach, it is definitely the most widely used and the one we’ve selected for our problem at hands), where a given decision will lead us down a different classification path.
Lemmatization
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma . If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. Stemming and lemmatization | Stanford.edu
Corpora
Topic Modeling
Word Embeddings
Summarizer
Ontologies
(aka knowledge graph) can incorporate computable descriptions that can bring insight in a wide set of compelling applications including more precise knowledge capture, semantic data integration, sophisticated query answering, and powerful association mining - thereby delivering key value for health care and the life sciences.
Natural Language Inference (NLI) and Recognizing Textual Entailment (RTE)
Identifying whether one piece of text can be plausibly inferred from another - automatic acquisition of paraphrases, lexical semantic relationships, inference methods, knowledge representations for applications such as question answering, information extraction and summarization.
Semantic Role Labeling (SRL)
identifies shallow semantic information in a given sentence. The tool labels verb-argument structure, identifying who did what to whom by assigning roles that indicate the agent, patient, and theme of each verb to constituents of the sentence representing entities related by the verb.
Deep Learning Algorithms
- Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Recurrent Neural Network (RNN)
- Deep Q Learning (DQN)
- 7 types of Artificial Neural Networks for Natural Language Processing
- Combination of Convolutional and Recurrent Neural Network for Sentiment Analysis of Short Texts | Xingyou Wang, Weijie Jiang, Zhiyong Luo
- Autoencoders / Encoder-Decoders
- LSTM
- GRU
Evaluation Measures - Classification Performance
Confusion Matrix, Precision, Recall, F Score, ROC Curves, trade off between True Positive Rate and False Positive Rate.
Capabilities
Sentiment Analysis
Wikifier