Vision
YouTube ... Quora ...Google search ...Google News ...Bing News
- Case Studies
- Capabilities
- Predict image
- Screening; Passenger, Luggage, & Cargo
- DeepLens - deep learning enabled video camera
- Rekognition Video
- Deep Learning (DL) Amazon Machine Image (AMI) - DLAMI
- Image Classification
- Image-to-Image Translation
- Landing AI ... LandingLens™, an enterprise AIOps/MLOps platform that offers to build, iterate, and operationalize AI powered visual inspection solutions for manufacturers
- Object Detection Using Convolutional Neural Networks | The Straight Dope
- Object detection with neural networks — a simple tutorial using keras | Johannes Rieke - Towards Data Science
- Object Localization and Detection | leonardoaraujosantos
- Why Tesla Invented A New Neural Network | Ambika Choudhury - Analytics India Magazine
- Introducing Segment Anything: Working toward the first foundation model for image segmentation | Meta AI ... identifying which image pixels belong to an object
Computer vision involves developing algorithms and techniques to enable computers to interpret, analyze, and understand visual data from the world around them. It focuses on developing methods for computers to perceive, analyze, and interpret digital images or videos in a way that simulates human vision. Computer vision involves tasks such as object detection, image recognition, segmentation, tracking, and scene reconstruction. It is used in a wide range of applications, including robotics, autonomous vehicles, security and surveillance, medical imaging, and augmented reality.
Contents
Vision Transformers (ViT)
YouTube ... Quora ...Google search ...Google News ...Bing News
- An Image is Worth 16x16 Words: Transformers for Image
- Vision transformer - Wikipedia
- Code a VISION - LLM w/ ViT, FLAN-T5 LLM & BLIP-2: Multimodal LLMs (MLLM)
- Vision Transformer (ViT) | Hugging Face
- google-research/vision_transformer - GitHub
- How the Vision Transformer (ViT) works in 10 minutes: an image is worth 16x16 words | Nikolas Adaloglou - AI Summer
ViT is a transformer that is targeted at vision processing tasks such as image recognition. It was first proposed in 2019 by Cordonnier et al. and later empirically evaluated more extensively in the well-known paper "An image is worth 16x16 words". ViT works by breaking down input images into a series of patches which, once transformed into vectors, are seen as words in a normal transformer. Each image is split into a sequence of fixed-size non-overlapping patches, which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be used for classification. The authors also add absolute position embeddings and feed the resulting sequence of vectors to a standard Transformer encoder. A [CLS] token is a special token that is used in classification tasks. It stands for “classification” and is used as the only input of the final MLP Head as it has been influenced by all the others. In the case of ViT, it is added to serve as representation of an entire image. The final MLP Head refers to the final Multi-Layer Perceptron (MLP) layer in the model. It takes the [CLS] token as input and outputs the final classification result.
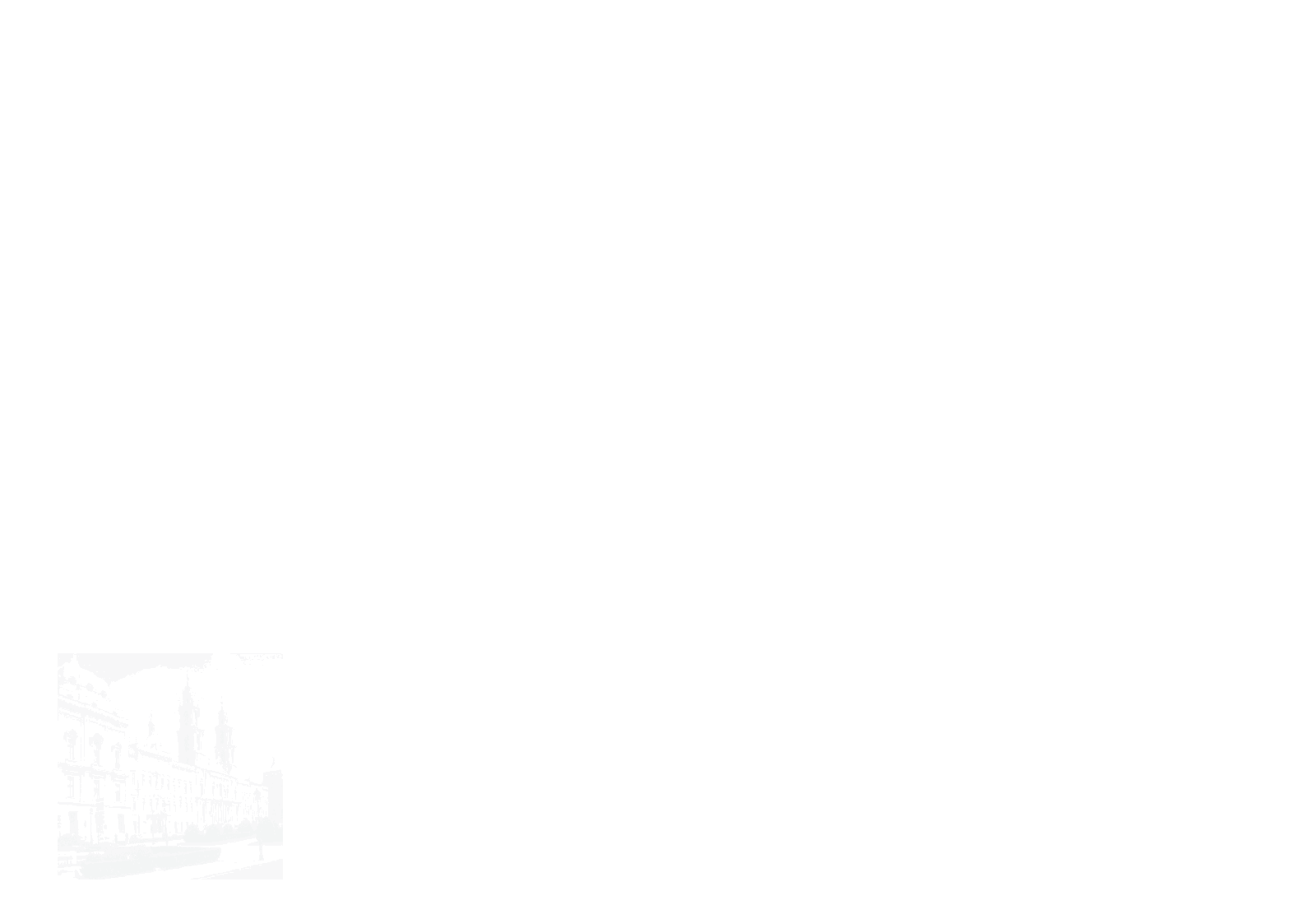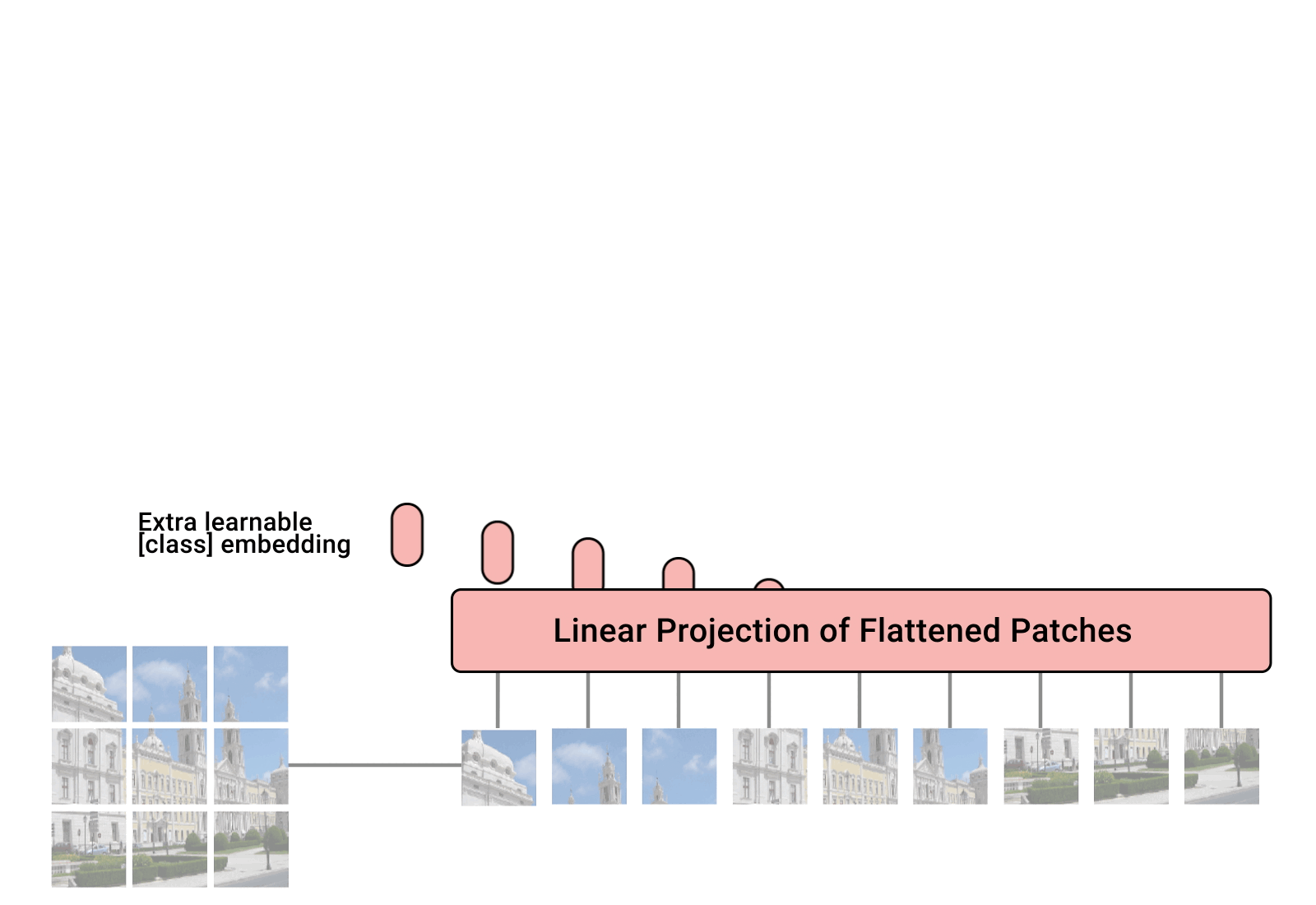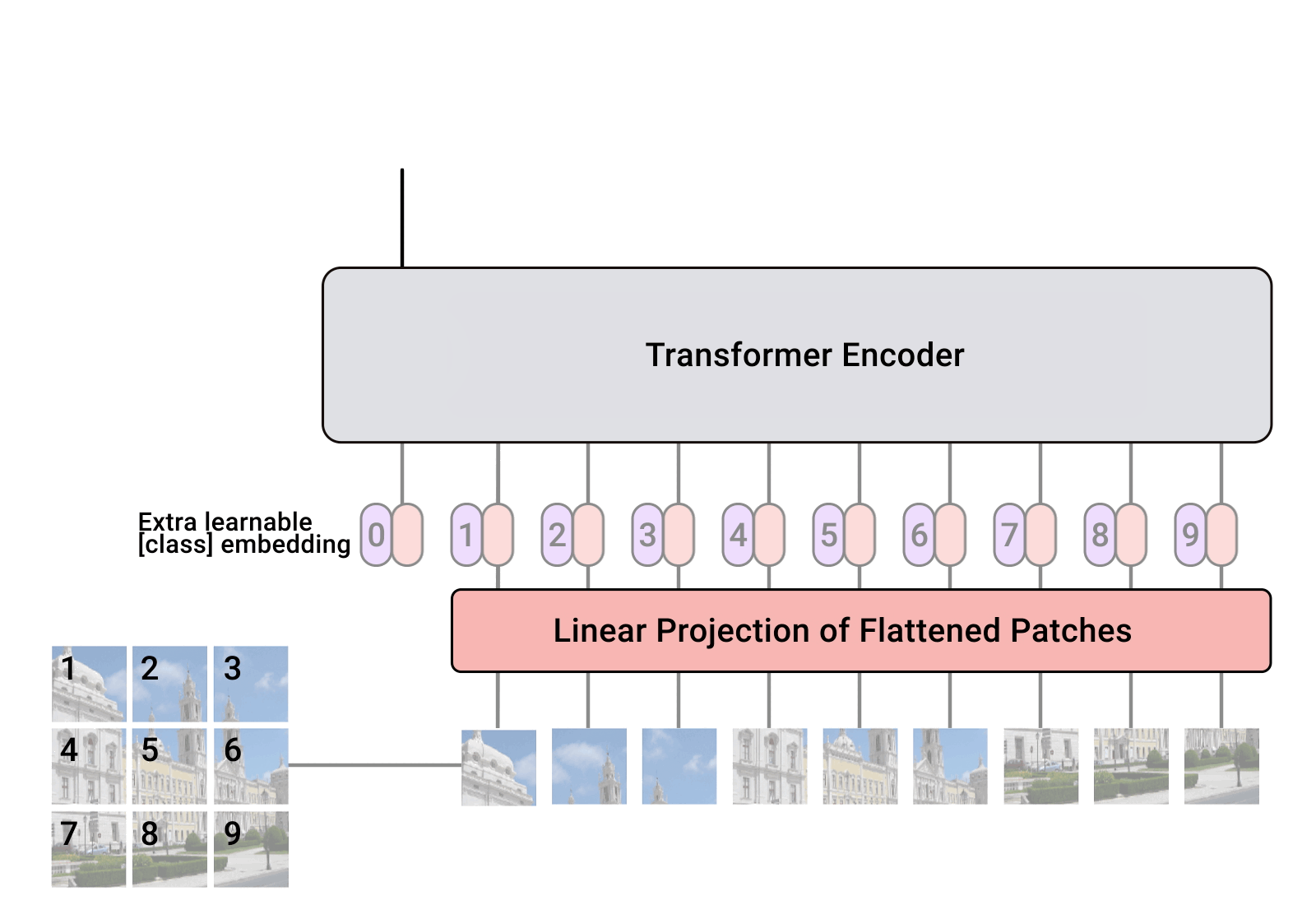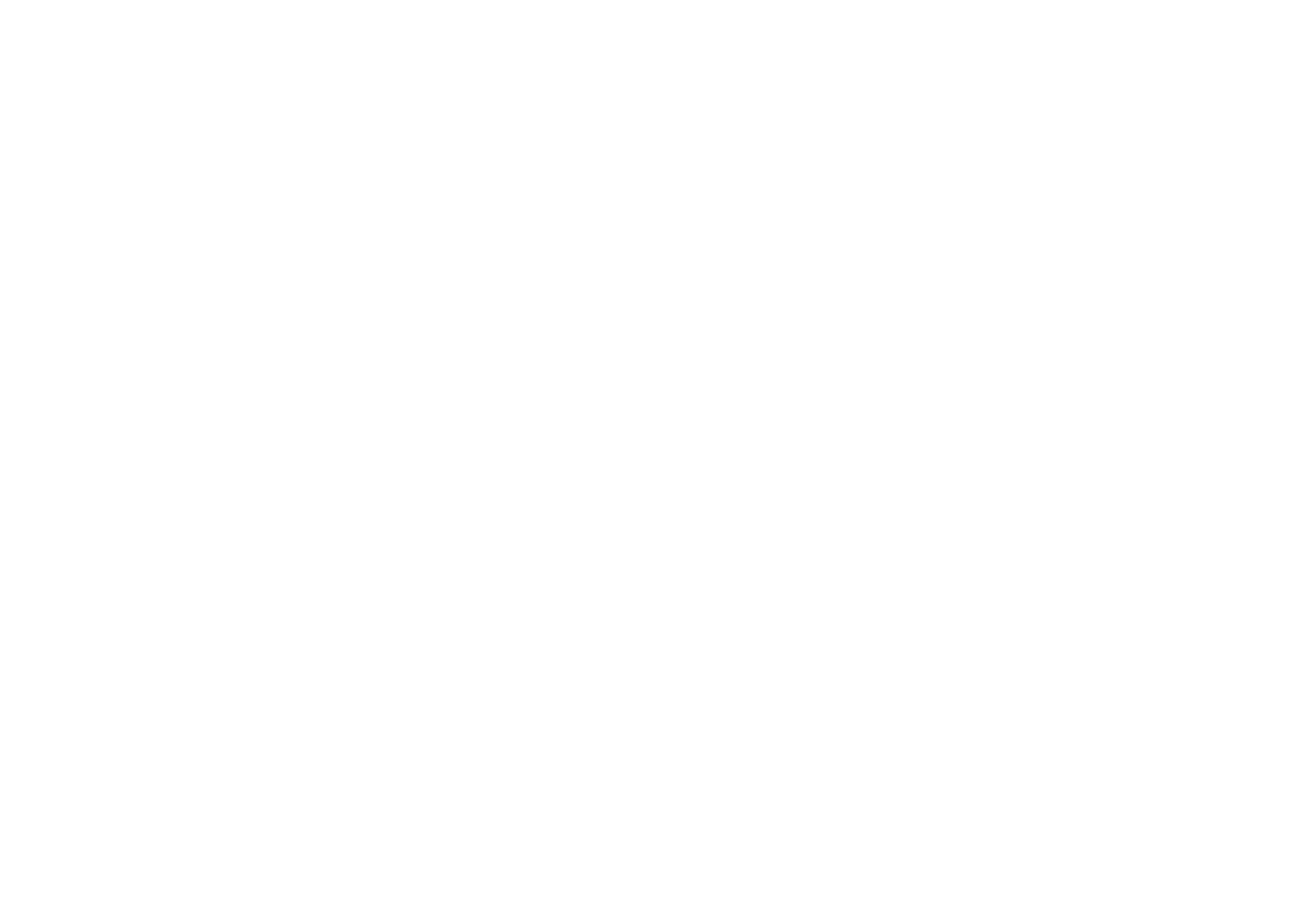
Image Retrieval / Object Detection
- Feature:
- Character Recognition
- (Deep) Convolutional Neural Network (DCNN/CNN)
- ResNet-50
- Getting Started & Project: Object Detection
Faster Region-based Convolutional Neural Networks (R-CNN), You only Look Once (YOLO), Single Shot Detector(SSD)
LiDAR