StructBERT
Youtube search... | ...Google search
- Natural Language Processing (NLP)
- StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding | W. Wang, B. Bi, M. Yan, C. Wu, J. Xia, Z. Bao, L. Peng and L. Si - Alibaba Group Inc.
Incorporating language structures into pre-training. Specifically, we pre-train StructBERT with two auxiliary tasks to make the most of the sequential order of words and sentences, which leverage language structures at the word and sentence levels, respectively. As a result, the new model is adapted to different levels of language understanding required by downstream tasks. StructBERT: Incorporating Language Structures Into Pretraining For Deep Language Understanding | W. Wang, B. Bi, M. Yan, C. Wu, J. Xia, Z. Bao, L. Peng and L. Si - Alibaba Group Inc.
Application
- COVID-19
- Fight Coronavirus - Part1 | Alibaba Cloud
- Fighting Coronavirus with Technology: Another Breakthrough for Alibaba in NLP Research
Hangzhou, China, March 6, 2020 – Alibaba's DAMO Academy, the group's global research program, has had another major breakthrough in the machine-reading capabilities that underpin success in artificial intelligence.
DAMO's Natural Language Processing (NLP) model topped the GLUE benchmark rankings, an industry table perceived as the most-important baseline test for the NLP model on March 3. Alibaba's model also significantly outperformed the human baselines, marking a key milestone in the development of robust natural language understanding systems.
DAMO's existing model has already been deployed widely in Alibaba's ecosystem, powering its customer-service AI chatbot and the search engine on Alibaba's retail platforms, as well as anonymous healthcare data analysis. The model was used in the text analysis of medical records and epidemiological investigation by CDCs in different cities in China for fighting against COVID-19.
StructBERT: Alibaba's Intelligent NLP Model General Language Understanding Evaluation (GLUE), a platform for evaluating and analyzing NLP systems, attracts global key AI players, including Google, Facebook, Microsoft, and Standard to participate every year. Alibaba's multitask machine-learning model, StructBERT, which is based on the pre-trained language model BERT, while also incorporating word and sentence structures, delivers impressive empirical results on a variety of downstream tasks, resulting in the GLUE benchmark as high as 90.3 – outperforming the human baselines of 87.1. It also boosts the performance in many language-understanding applications, such as sentiment analysis, textual entailment and question-answering.
This is not the first time Alibaba's machine-learning model has topped others. On June 20 2019, Alibaba's model bested human scores when tested by the Microsoft Machine Reading Comprehension dataset, one of the artificial-intelligence world's most challenging tests for reading comprehension. The model scored 0.54 in the MS Marco question-answering task, outperforming the human score of 0.539, a benchmark provided by Microsoft. In 2018, Alibaba also scored higher than the human benchmark in the Stanford Question Answering Dataset – also one of the most-popular machine reading-comprehension challenges worldwide.
What Makes StructBERT So Good? To better understand StructBERT, let's take a quick recap to the core concepts of NLP. A pre-trained language model (LM) is a key component in many natural language understanding (NLU) tasks such as semantic textual similarity, question answering, and sentiment classification. In order to obtain reliable language representations, neural language models are designed to define the joint probability function of sequences of words in text with self-supervised learning. Different from traditional word-specific embedding in which each token is assigned a global representation, recent work such as BERT derives contextualized word vectors from a language model trained on a large text corpus. In plain terms, this means that these models are "context-sensitive".
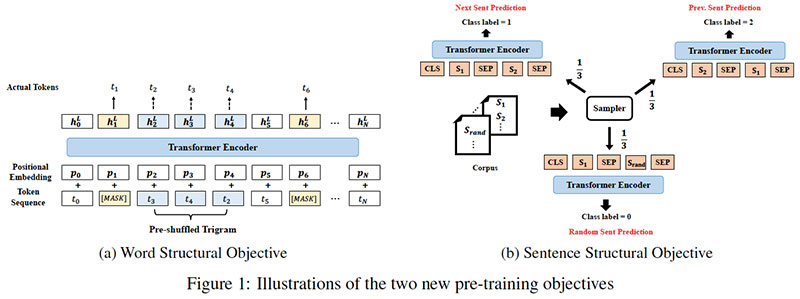
However, existing models have limitations and do not make the most of underlying language structures. Since language fluency is determined by the ordering of words and sentences, finding the best permutation of a set of words and sentences is an essential problem in many NLP tasks, such as machine translation and NLU. StructBERT incorporates language structures into BERT pre-training by proposing two novel linearization strategies. Specifically, in addition to the existing masking strategy, StructBERT extends BERT by leveraging the structural information: word-level ordering and sentence-level ordering.
In StructBERT, model pre-training is augmented with two new structural objectives on the inner-sentence and inter-sentence structures, respectively. In this way, the linguistic aspects are explicitly captured during the pre-training procedure. With structural pre-training, StructBERT encodes dependency between words as well as sentences in the contextualized representation, which provides the model with better generalizability and adaptability.
Fighting Coronavirus with Technology Over the past months, Alibaba has leveraged its proprietary technologies to help contain the coronavirus outbreak. Alibaba DAMO Academy has teamed up with Chinese medical institutions to develop an AI system that can expedite diagnosis and analysis of the virus. In February, Alibaba Cloud made its cloud-based AI-powered computing platform available for free to global research institutions to accelerate viral gene-sequencing, protein-screening and other research in treating or preventing the virus. Technologies like StructBERT and other cutting-edge research by Alibaba DAMO Academy help us better cope with real-life situations and challenges, such as the recent epidemic.