Difference between revisions of "Few Shot Learning"
| Line 5: | Line 5: | ||
* [[Multitask Learning]] | * [[Multitask Learning]] | ||
* [http://medium.com/quick-code/understanding-few-shot-learning-in-machine-learning-bede251a0f67 Understanding few-shot learning in machine learning | Michael J. Garbade] | * [http://medium.com/quick-code/understanding-few-shot-learning-in-machine-learning-bede251a0f67 Understanding few-shot learning in machine learning | Michael J. Garbade] | ||
| − | + | ||
| − | |||
| + | |||
| + | <youtube>Q-agrHm-ztU</youtube> | ||
| + | <youtube>LMfLRF9VKrc</youtube> | ||
| + | |||
| + | == [http://towardsdatascience.com/advances-in-few-shot-learning-a-guided-tour-36bc10a68b77 Advances in few-shot learning: a guided tour | Oscar Knagg] == | ||
| + | |||
| + | * [http://towardsdatascience.com/advances-in-few-shot-learning-reproducing-results-in-pytorch-aba70dee541d Advances in few-shot learning: reproducing results in PyTorch | Oscar Knagg- Towards Data Science] | ||
| + | |||
* [http://arxiv.org/pdf/1606.04080.pdf Matching Networks: A differentiable nearest-neighbors classifier] | * [http://arxiv.org/pdf/1606.04080.pdf Matching Networks: A differentiable nearest-neighbors classifier] | ||
* [http://arxiv.org/pdf/1703.05175.pdf Prototypical Networks: Learning prototypical representations] | * [http://arxiv.org/pdf/1703.05175.pdf Prototypical Networks: Learning prototypical representations] | ||
| Line 13: | Line 20: | ||
| − | + | === N-shot, k-way classification tasks === | |
| − | + | ||
| + | The ability of a algorithm to perform few-shot learning is typically measured by its performance on n-shot, k-way tasks. These are run as follows: | ||
| + | |||
| + | # A model is given a query sample belonging to a new, previously unseen class | ||
| + | # It is also given a support set, S, consisting of n examples each from k different unseen classes | ||
| + | # The algorithm then has to determine which of the support set classes the query sample belongs to | ||
| + | |||
| + | |||
| + | === Matching Networks === | ||
| + | |||
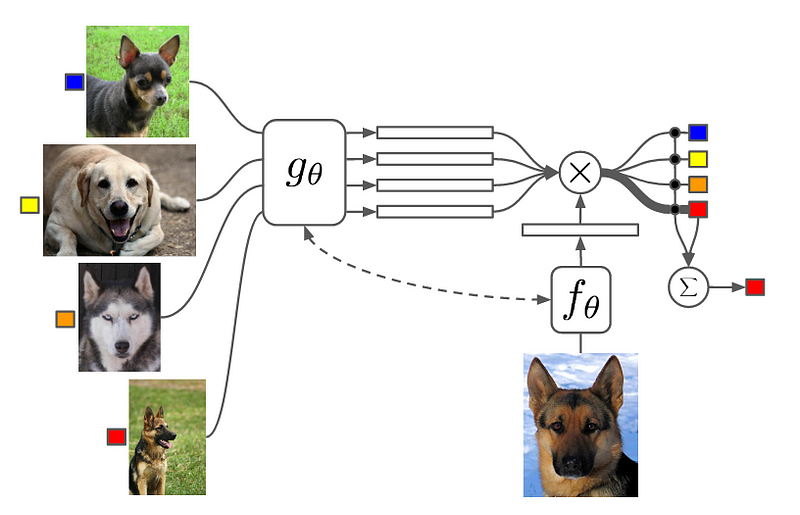
| + | combine both embedding and classification to form an end-to-end differentiable nearest neighbors classifier. | ||
| + | |||
| + | # Embed a high dimensional sample into a low dimensional space | ||
| + | # Perform a generalized form of nearest-neighbors classification | ||
| + | |||
| + | The meaning of this is that the prediction of the model, y^, is the weighted sum of the labels, y_i, of the support set, where the weights are a pairwise similarity function, a(x^, x_i), between the query example, x^, and a support set samples, x_i. The labels y_i in this equation are one-hot encoded label vectors. | ||
| + | |||
| + | Matching Networks are end-to-end differentiable provided the attention function a(x^, x_i) is differentiable. | ||
| + | |||
| + | http://cdn-images-1.medium.com/max/800/1*OkiAPbdYq1utWUGlDGuBKw.png | ||
| + | |||
| + | === Prototypical Networks === | ||
Revision as of 14:52, 4 January 2019
YouTube search... ...Google search
- Transfer Learning
- Multitask Learning
- Understanding few-shot learning in machine learning | Michael J. Garbade
Contents
Advances in few-shot learning: a guided tour | Oscar Knagg
- Matching Networks: A differentiable nearest-neighbors classifier
- Prototypical Networks: Learning prototypical representations
- Model-agnostic Meta-Learning: Learning to fine-tune
N-shot, k-way classification tasks
The ability of a algorithm to perform few-shot learning is typically measured by its performance on n-shot, k-way tasks. These are run as follows:
- A model is given a query sample belonging to a new, previously unseen class
- It is also given a support set, S, consisting of n examples each from k different unseen classes
- The algorithm then has to determine which of the support set classes the query sample belongs to
Matching Networks
combine both embedding and classification to form an end-to-end differentiable nearest neighbors classifier.
- Embed a high dimensional sample into a low dimensional space
- Perform a generalized form of nearest-neighbors classification
The meaning of this is that the prediction of the model, y^, is the weighted sum of the labels, y_i, of the support set, where the weights are a pairwise similarity function, a(x^, x_i), between the query example, x^, and a support set samples, x_i. The labels y_i in this equation are one-hot encoded label vectors.
Matching Networks are end-to-end differentiable provided the attention function a(x^, x_i) is differentiable.