Difference between revisions of "Bayes"
m (→Bayesian Parameter Averaging (BPA)) |
m (→Bayesian Linear Regression) |
||
| Line 53: | Line 53: | ||
<youtube>lvFi02LV82g</youtube> | <youtube>lvFi02LV82g</youtube> | ||
| − | = <span id="Bayesian Linear Regression"></span>Bayesian Linear Regression = | + | = <span id="Bayes Linear Statistics"></span>Bayes Linear Statistics = |
| − | [http://www.youtube.com/results?search_query=Bayesian+Linear+Regression YouTube search...] | + | [http://www.youtube.com/results?search_query=Bayes+Linear+Statistics+ai YouTube search...] |
| − | [http://www.google.com/search?q=Bayesian+Linear+Regression+ | + | [http://www.google.com/search?q=Bayes+Linear+Statistics+ai ...Google search] |
| + | |||
| + | Bayes linear statistics is a subjectivist statistical methodology and framework. Traditional subjective Bayesian analysis is based upon fully specified probability distributions, which are very difficult to specify at the necessary level of detail. Bayes linear analysis attempts to solve this problem by developing theory and practise for using partially specified probability models. Bayes linear in its current form has been primarily developed by Michael Goldstein. [http://en.wikipedia.org/wiki/Bayes_linear_statistics Bayes Linear Statistics | Wikipedia] | ||
| + | |||
| + | <youtube>ySP91xZ9naI</youtube> | ||
| + | |||
| + | == <span id="Bayesian Linear Regression"></span>Bayesian Linear Regression == | ||
| + | [http://www.youtube.com/results?search_query=Bayesian+Linear+Regression+ai YouTube search...] | ||
| + | [http://www.google.com/search?q=Bayesian+Linear+Regression+ai ...Google search] | ||
* [[Regression]] Analysis | * [[Regression]] Analysis | ||
| Line 73: | Line 81: | ||
Bayesian methods have a highly desirable quality: they avoid overfitting. They do this by making some assumptions beforehand about the likely distribution of the answer. Another byproduct of this approach is that they have very few parameters. Machine Learning has both Bayesian algorithms for both classification (Two-class Bayes' point machine) and regression (Bayesian linear regression). Note that these assume that the data can be split or fit with a straight line. - Dinesh Chandrasekar | Bayesian methods have a highly desirable quality: they avoid overfitting. They do this by making some assumptions beforehand about the likely distribution of the answer. Another byproduct of this approach is that they have very few parameters. Machine Learning has both Bayesian algorithms for both classification (Two-class Bayes' point machine) and regression (Bayesian linear regression). Note that these assume that the data can be split or fit with a straight line. - Dinesh Chandrasekar | ||
| − | |||
= <span id="Bayesian Deep Learning (BDL)"></span>Bayesian Deep Learning (BDL) = | = <span id="Bayesian Deep Learning (BDL)"></span>Bayesian Deep Learning (BDL) = | ||
Revision as of 20:57, 11 October 2020
Youtube search... ...Google search
- AI Solver
- Capabilities
- Statistics for Intelligence
- Feature Engineering and Selection: A Practical Approach for Predictive Models - 12.1 Naive Bayes Models | Max Kuhn and Kjell Johnson
This algorithm is based on the “Bayes’ Theorem” in probability. Due to that Naive Bayes can be applied only if the features are independent of each other since it is a requirement in Bayes’ Theorem. If we try to predict a flower type by its petal length and width, we can use Naive Bayes approach since both those features are independent. 10 Machine Learning Algorithms You need to Know | Sidath Asir @ Medium
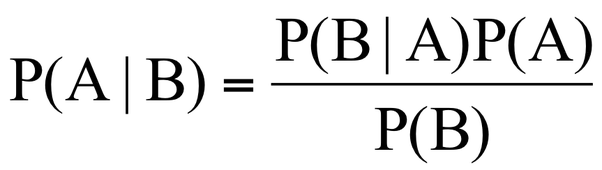
Contents
Bayes' Theorem
the probability of an event, based on prior knowledge of conditions that might be related to the event. Bayes' Theorem | Wikipedia
Bayesian Statistics
Bayesian Hypothesis Testing
Naive Bayes
- How to Develop a Naive Bayes Classifier from Scratch in Python | Jason Brownlee - Machine Learning Mastery
- A Beginner's Guide to Bayes' Theorem, Naive Bayes Classifiers and Bayesian Networks | Chris Nicholson - A.I. Wiki pathmind
A Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. For example, a fruit may be considered to be an apple if it is red, round, and about 3 inches in diameter. Even if these features depend on each other or upon the existence of the other features, all of these properties independently contribute to the probability that this fruit is an apple and that is why it is known as ‘Naive’.
Two-Class Bayes Point Machine
This algorithm efficiently approximates the theoretically optimal Bayesian average of linear classifiers (in terms of generalization performance) by choosing one "average" classifier, the Bayes Point. Because the Bayes Point Machine is a Bayesian classification model, it is not prone to overfitting to the training data. - Microsoft
Bayes Linear Statistics
YouTube search... ...Google search
Bayes linear statistics is a subjectivist statistical methodology and framework. Traditional subjective Bayesian analysis is based upon fully specified probability distributions, which are very difficult to specify at the necessary level of detail. Bayes linear analysis attempts to solve this problem by developing theory and practise for using partially specified probability models. Bayes linear in its current form has been primarily developed by Michael Goldstein. Bayes Linear Statistics | Wikipedia
Bayesian Linear Regression
YouTube search... ...Google search
- Regression Analysis
- Bayesian Linear Regression | Microsoft
- 10 types of regressions. Which one to use? | Vincent Granville
The aim of Bayesian Linear Regression is not to find the single “best” value of the model parameters, but rather to determine the posterior distribution for the model parameters. Not only is the response generated from a probability distribution, but the model parameters are assumed to come from a distribution as well. Introduction to Bayesian Linear Regression | Towards Data Science
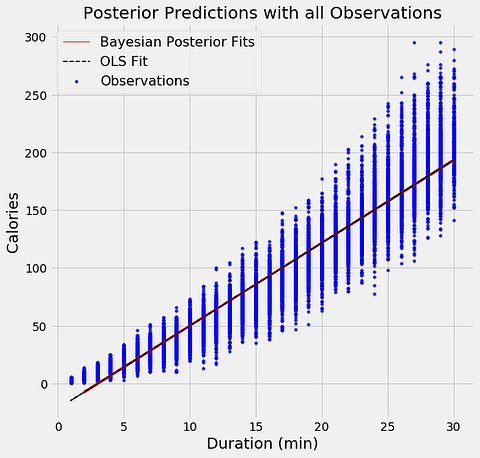
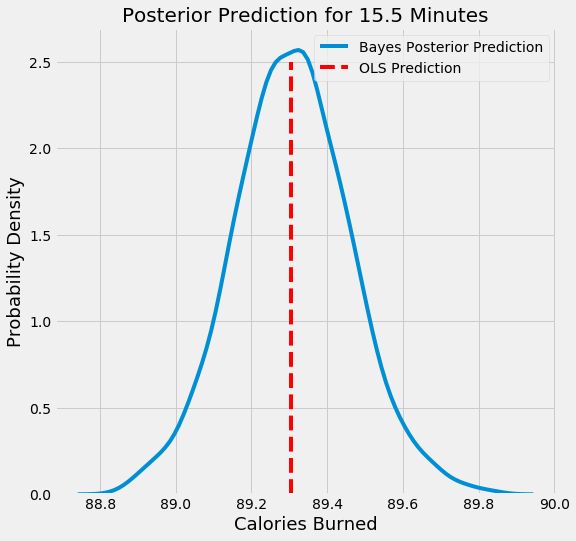
In the Bayesian viewpoint, we formulate linear regression using probability distributions rather than point estimates. The response, y, is not estimated as a single value, but is assumed to be drawn from a probability distribution. The output, y is generated from a normal (Gaussian) Distribution characterized by a mean and variance. The mean for linear regression is the transpose of the weight matrix multiplied by the predictor matrix. The variance is the square of the standard deviation σ (multiplied by the Identity matrix because this is a multi-dimensional formulation of the model).
Bayesian methods have a highly desirable quality: they avoid overfitting. They do this by making some assumptions beforehand about the likely distribution of the answer. Another byproduct of this approach is that they have very few parameters. Machine Learning has both Bayesian algorithms for both classification (Two-class Bayes' point machine) and regression (Bayesian linear regression). Note that these assume that the data can be split or fit with a straight line. - Dinesh Chandrasekar
Bayesian Deep Learning (BDL)
Youtube search... ...Google search
BDL provides a deep learning framework which can also model uncertainty. BDL can achieve state-of-the-art results, while also understanding uncertainty. Deep Learning Is Not Good Enough, We Need Bayesian Deep Learning for Safe AI | Alex Kendall
Bayes Estimator
Youtube search... ...Google search
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function (i.e., the posterior expected loss). Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation. Bayes Estimator | Wikipedia
Bayesian Parameter Estimation
Bayesian Network
Youtube search... ...Google search
A Bayesian network (also known as a Bayes network, belief network, or decision network) is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases. Efficient algorithms can perform inference and learning in Bayesian networks. Bayesian networks that model sequences of variables (e.g. speech signals or protein sequences) are called dynamic Bayesian networks. Generalizations of Bayesian networks that can represent and solve decision problems under uncertainty are called influence diagrams. Bayesian Network | Wikipedia
Dynamic Bayesian Network (DBN)
Youtube search... ...Google search
A Dynamic Bayesian Network (DBN) is a Bayesian network (BN) which relates variables to each other over adjacent time steps. This is often called a Two-Timeslice BN (2TBN) because it says that at any point in time T, the value of a variable can be calculated from the internal regressors and the immediate prior value (time T-1). DBNs were developed by Paul Dagum in the early 1990s at Stanford University's Section on Medical Informatics. Dagum developed DBNs to unify and extend traditional linear state-space models such as Kalman filters, linear and normal forecasting models such as ARMA and simple dependency models such as hidden Markov models into a general probabilistic representation and inference mechanism for arbitrary nonlinear and non-normal time-dependent domains. Today, DBNs are common in robotics, and have shown potential for a wide range of data mining applications. For example, they have been used in speech recognition, digital forensics, protein sequencing, and bioinformatics. DBN is a generalization of hidden Markov models and Kalman filters. Dynamic Bayesian Network (DBN) | Wikipedia
Ensemble Learning
Bayes Optimal Classifier (BOC)
Youtube search... ...Google search
The Bayes optimal classifier is a classification technique. It is an ensemble of all the hypotheses in the hypothesis space. On average, no other ensemble can outperform it.[13] The naive Bayes optimal classifier is a version of this that assumes that the data is conditionally independent on the class and makes the computation more feasible. Each hypothesis is given a vote proportional to the likelihood that the training dataset would be sampled from a system if that hypothesis were true. To facilitate training data of finite size, the vote of each hypothesis is also multiplied by the prior probability of that hypothesis. Bayes Optimal Classifier (BOC) | Wikipedia
Bayesian Model Averaging (BMA)
Youtube search... ...Google search
Bayesian model averaging (BMA) makes predictions using an average over several models with weights given by the posterior probability of each model given the data.[15] BMA is known to generally give better answers than a single model, obtained, e.g., via stepwise regression, especially where very different models have nearly identical performance in the training set but may otherwise perform quite differently. The most obvious question with any technique that uses Bayes' theorem is the prior, i.e., a specification of the probability (subjective, perhaps) that each model is the best to use for a given purpose. Conceptually, BMA can be used with any prior. Bayesian Model Averaging (BMA) | Wikipedia
Bayesian Model Combination (BMC)
Youtube search... ...Google search
Bayesian model combination (BMC) is an algorithmic correction to Bayesian model averaging (BMA). Instead of sampling each model in the ensemble individually, it samples from the space of possible ensembles (with model weightings drawn randomly from a Dirichlet distribution having uniform parameters). This modification overcomes the tendency of BMA to converge toward giving all of the weight to a single model. Although BMC is somewhat more computationally expensive than BMA, it tends to yield dramatically better results. The results from BMC have been shown to be better on average (with statistical significance) than BMA, and bagging. The use of Bayes' law to compute model weights necessitates computing the probability of the data given each model. Typically, none of the models in the ensemble are exactly the distribution from which the training data were generated, so all of them correctly receive a value close to zero for this term. This would work well if the ensemble were big enough to sample the entire model-space, but such is rarely possible. Consequently, each pattern in the training data will cause the ensemble weight to shift toward the model in the ensemble that is closest to the distribution of the training data. It essentially reduces to an unnecessarily complex method for doing model selection. The possible weightings for an ensemble can be visualized as lying on a simplex. At each vertex of the simplex, all of the weight is given to a single model in the ensemble. BMA converges toward the vertex that is closest to the distribution of the training data. By contrast, BMC converges toward the point where this distribution projects onto the simplex. In other words, instead of selecting the one model that is closest to the generating distribution, it seeks the combination of models that is closest to the generating distribution. The results from BMA can often be approximated by using cross-validation to select the best model from a bucket of models. Likewise, the results from BMC may be approximated by using cross-validation to select the best ensemble combination from a random sampling of possible weightings. Bayesian Model Combination (BMC) | Wikipedia