Difference between revisions of "Self-Supervised"
| Line 16: | Line 16: | ||
* [[Generative Adversarial Network (GAN)]] | * [[Generative Adversarial Network (GAN)]] | ||
| − | <img src="http://lilianweng.github.io/lil-log/assets/images/grasp2vec.png" width="700" height=" | + | <img src="http://lilianweng.github.io/lil-log/assets/images/grasp2vec.png" width="700" height="350"> |
[[Reinforcement Learning (RL)]] Control-based: When running a RL policy in the real world, such as controlling a physical robot on visual inputs, it is non-trivial to properly track states, obtain reward signals or determine whether a goal is achieved for real. The visual data has a lot of noise that is irrelevant to the true state and thus the equivalence of states cannot be inferred from pixel-level comparison. Self-supervised representation learning has shown great potential in learning useful state embedding that can be used directly as input to a control policy. | [[Reinforcement Learning (RL)]] Control-based: When running a RL policy in the real world, such as controlling a physical robot on visual inputs, it is non-trivial to properly track states, obtain reward signals or determine whether a goal is achieved for real. The visual data has a lot of noise that is irrelevant to the true state and thus the equivalence of states cannot be inferred from pixel-level comparison. Self-supervised representation learning has shown great potential in learning useful state embedding that can be used directly as input to a control policy. | ||
Revision as of 13:31, 8 December 2019
YouTube search... ...Google search
- Supervised Learning
- Unsupervised Learning
Self-supervised learning refers to an unsupervised learning problem that is framed as a supervised learning problem in order to apply supervised learning algorithms to solve it. Supervised learning algorithms are used to solve an alternate or pretext task, the result of which is a model or representation that can be used in the solution of the original (actual) modeling problem. A common example of self-supervised learning is computer vision where a corpus of unlabeled images is available and can be used to train a supervised model, such as making images grayscale and having a model predict a color representation (colorization) or removing blocks of the image and have a model predict the missing parts (inpainting). 14 Different Types of Learning in Machine Learning | Jason Brownlee - Machine Learning Mastery
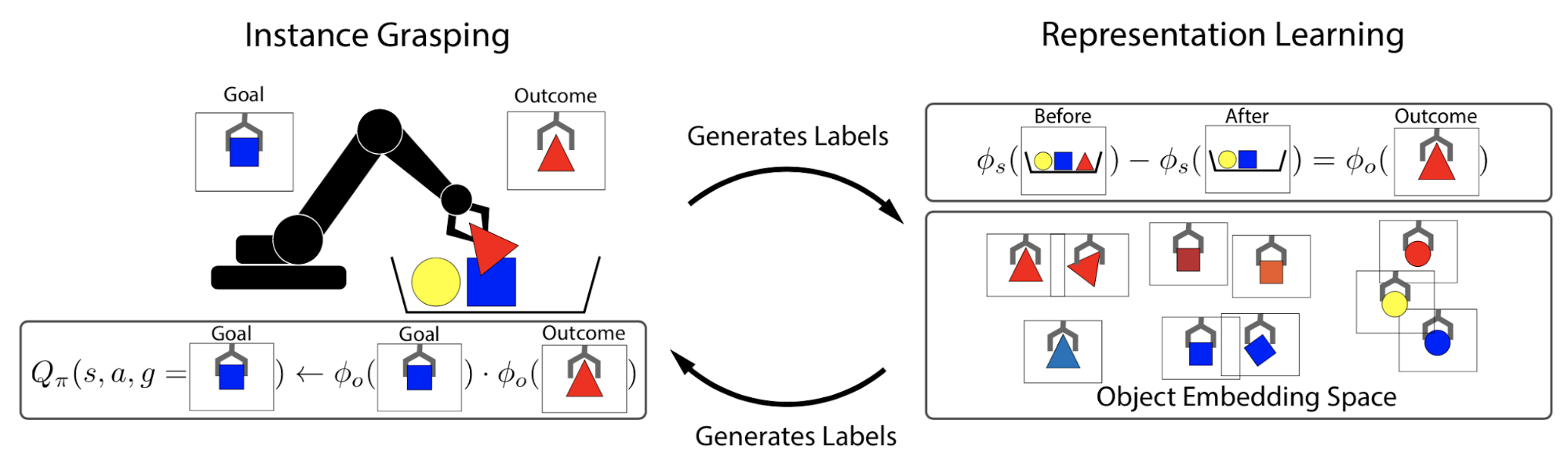
Reinforcement Learning (RL) Control-based: When running a RL policy in the real world, such as controlling a physical robot on visual inputs, it is non-trivial to properly track states, obtain reward signals or determine whether a goal is achieved for real. The visual data has a lot of noise that is irrelevant to the true state and thus the equivalence of states cannot be inferred from pixel-level comparison. Self-supervised representation learning has shown great potential in learning useful state embedding that can be used directly as input to a control policy.
Given a task and enough labels, supervised learning can solve it really well. Good performance usually requires a decent amount of labels, but collecting manual labels is expensive (i.e. ImageNet) and hard to be scaled up. Considering the amount of unlabelled data (e.g. free text, all the images on the Internet) is substantially more than a limited number of human curated labelled Datasets, it is kinda wasteful not to use them. However, unsupervised learning is not easy and usually works much less efficiently than supervised learning. What if we can get labels for free for unlabelled data and train unsupervised dataset in a supervised manner? We can achieve this by framing a supervised learning task in a special form to predict only a subset of information using the rest. In this way, all the information needed, both inputs and labels, has been provided. This is known as self-supervised learning. This idea has been widely used in language modeling. The default task for a language model is to predict the next word given the past sequence. Bidirectional Encoder Representations from Transformers (BERT) adds two other auxiliary tasks and both rely on self-generated labels.
Why Self-Supervised Learning? Self-supervised learning empowers us to exploit a variety of labels that come with the data for free. The motivation is quite straightforward. Producing a dataset with clean labels is expensive but unlabeled data is being generated all the time. To make use of this much larger amount of unlabeled data, one way is to set the learning objectives properly so as to get supervision from the data itself. The self-supervised task, also known as pretext task, guides us to a supervised loss function. However, we usually don’t care about the final performance of this invented task. Rather we are interested in the learned intermediate representation with the expectation that this representation can carry good semantic or structural meanings and can be beneficial to a variety of practical downstream tasks. Self-Supervised Representation Learning | Lilian Weng - Lil'Log