Difference between revisions of "Generative Pre-trained Transformer (GPT)"
| Line 21: | Line 21: | ||
a text-generating bot based on a model with 1.5 billion parameters. ...Ultimately, OpenAI's researchers kept the full thing to themselves, only releasing a pared-down 117 million parameter version of the model (which we have dubbed "GPT-2 Junior") as a safer demonstration of what the full GPT-2 model could do.[http://arstechnica.com/information-technology/2019/02/researchers-scared-by-their-own-work-hold-back-deepfakes-for-text-ai/ Twenty minutes into the future with OpenAI’s Deep Fake Text AI | Sean Gallagher] | a text-generating bot based on a model with 1.5 billion parameters. ...Ultimately, OpenAI's researchers kept the full thing to themselves, only releasing a pared-down 117 million parameter version of the model (which we have dubbed "GPT-2 Junior") as a safer demonstration of what the full GPT-2 model could do.[http://arstechnica.com/information-technology/2019/02/researchers-scared-by-their-own-work-hold-back-deepfakes-for-text-ai/ Twenty minutes into the future with OpenAI’s Deep Fake Text AI | Sean Gallagher] | ||
| + | |||
| + | [http://talktotransformer.com/ Try GPT-2] | ||
http://cdn-images-1.medium.com/max/800/1*jbcwhhB8PEpJRk781rML_g.png | http://cdn-images-1.medium.com/max/800/1*jbcwhhB8PEpJRk781rML_g.png | ||
| − | <youtube> | + | <youtube>0OtZ8dUFxXA</youtube> |
| + | <youtube>8ypnLjwpzK8</youtube> | ||
<youtube>LWDbAoPyQAk</youtube> | <youtube>LWDbAoPyQAk</youtube> | ||
<youtube>H1lncbq8NC0</youtube> | <youtube>H1lncbq8NC0</youtube> | ||
<youtube>2hpB_H_QMRk</youtube> | <youtube>2hpB_H_QMRk</youtube> | ||
<youtube>u1_qMdb0kYU</youtube> | <youtube>u1_qMdb0kYU</youtube> | ||
| − | <youtube> | + | <youtube>0n95f-eqZdw</youtube> |
== r/SubSimulator == | == r/SubSimulator == | ||
Revision as of 08:13, 25 October 2019
YouTube search... ...Google search
- Natural Language Generation (NLG)
- Language Models are Unsupervised Multitask Learners | Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever
- (117M parameter) version of GPT-2 | GitHub
- GPT-2: It learned on the Internet | Janelle Shane
- Attention Mechanism/Transformer Model
- Neural Monkey | Jindřich Libovický, Jindřich Helcl, Tomáš Musil Byte Pair Encoding (BPE) enables NMT model translation on open-vocabulary by encoding rare and unknown words as sequences of subword units.
- Too powerful NLP model (GPT-2): What is Generative Pre-Training | Edward Ma
- Bidirectional Encoder Representations from Transformers (BERT)
- ELMo
- Language Models are Unsupervised Multitask Learners - GitHub
- OpenAI Creates Platform for Generating Fake News. Wonderful | Nick Kolakowski - Dice
a text-generating bot based on a model with 1.5 billion parameters. ...Ultimately, OpenAI's researchers kept the full thing to themselves, only releasing a pared-down 117 million parameter version of the model (which we have dubbed "GPT-2 Junior") as a safer demonstration of what the full GPT-2 model could do.Twenty minutes into the future with OpenAI’s Deep Fake Text AI | Sean Gallagher
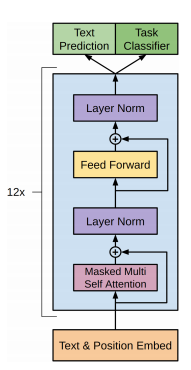
r/SubSimulator
Subreddit populated entirely by AI personifications of other subreddits -- all posts and comments are generated automatically using:
results in coherent and realistic simulated content.
GetBadNews
- Get Bad News game - Can you beat my score? Play the fake news game! Drop all pretense of ethics and choose the path that builds your persona as an unscrupulous media magnate. Your task is to get as many followers as you can while
