Difference between revisions of "Mean-Shift Clustering"
m |
|||
| Line 2: | Line 2: | ||
|title=PRIMO.ai | |title=PRIMO.ai | ||
|titlemode=append | |titlemode=append | ||
| − | |keywords=artificial, intelligence, machine, learning, models | + | |keywords=ChatGPT, artificial, intelligence, machine, learning, GPT-4, GPT-5, NLP, NLG, NLC, NLU, models, data, singularity, moonshot, Sentience, AGI, Emergence, Moonshot, Explainable, TensorFlow, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Hugging Face, OpenAI, Tensorflow, OpenAI, Google, Nvidia, Microsoft, Azure, Amazon, AWS, Meta, LLM, metaverse, assistants, agents, digital twin, IoT, Transhumanism, Immersive Reality, Generative AI, Conversational AI, Perplexity, Bing, You, Bard, Ernie, prompt Engineering LangChain, Video/Image, Vision, End-to-End Speech, Synthesize Speech, Speech Recognition, Stanford, MIT |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools |
| − | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | + | |
| + | <!-- Google tag (gtag.js) --> | ||
| + | <script async src="https://www.googletagmanager.com/gtag/js?id=G-4GCWLBVJ7T"></script> | ||
| + | <script> | ||
| + | window.dataLayer = window.dataLayer || []; | ||
| + | function gtag(){dataLayer.push(arguments);} | ||
| + | gtag('js', new Date()); | ||
| + | |||
| + | gtag('config', 'G-4GCWLBVJ7T'); | ||
| + | </script> | ||
}} | }} | ||
[http://www.youtube.com/results?search_query=Mean+Shift+Clustering Youtube search...] | [http://www.youtube.com/results?search_query=Mean+Shift+Clustering Youtube search...] | ||
| Line 10: | Line 19: | ||
* [[AI Solver]] | * [[AI Solver]] | ||
** [[...cluster]] | ** [[...cluster]] | ||
| − | |||
* [[Clustering]] | * [[Clustering]] | ||
Revision as of 21:40, 5 July 2023
Youtube search... ...Google search
Mean shift clustering is a sliding-window-based algorithm that attempts to find dense areas of data points. It is a centroid-based algorithm meaning that the goal is to locate the center points of each group/class, which works by updating candidates for center points to be the mean of the points within the sliding-window. These candidate windows are then filtered in a post-processing stage to eliminate near-duplicates, forming the final set of center points and their corresponding groups. The 5 Clustering Algorithms Data Scientists Need to Know | Towards Data Science
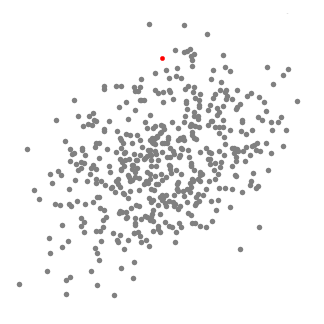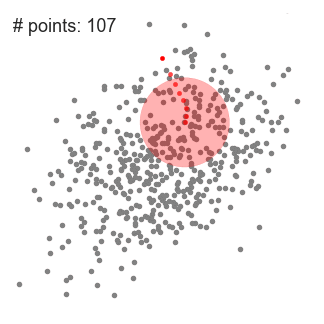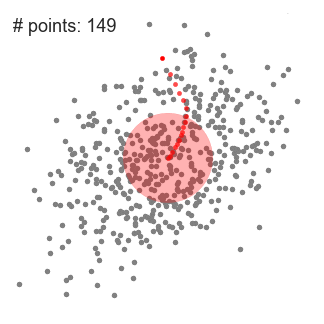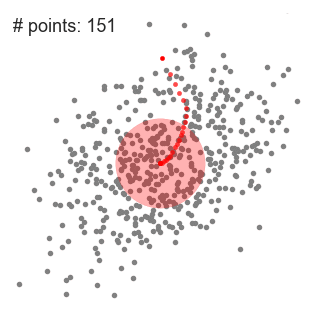
An illustration of the entire process from end-to-end with all of the sliding windows is show below. Each black dot represents the centroid of a sliding window and each gray dot is a data point.

In contrast to K-means clustering there is no need to select the number of clusters as mean-shift automatically discovers this. That’s a massive advantage. The fact that the cluster centers converge towards the points of maximum density is also quite desirable as it is quite intuitive to understand and fits well in a naturally data-driven sense. The drawback is that the selection of the window size/radius “r” can be non-trivial.