Difference between revisions of "Quantization"
| Line 7: | Line 7: | ||
[http://www.youtube.com/results?search_query=Quantization+aware+model+training YouTube search...] | [http://www.youtube.com/results?search_query=Quantization+aware+model+training YouTube search...] | ||
[http://www.google.com/search?q=Quantization+aware+model+training ...Google search] | [http://www.google.com/search?q=Quantization+aware+model+training ...Google search] | ||
| + | |||
| + | |||
| + | * [http://petewarden.com/2016/05/03/how-to-quantize-neural-networks-with-tensorflow/ How to Quantize Neural Networks with TensorFlow | Pete Warden] | ||
| + | * [http://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd 8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision | Manas Sahni] | ||
| + | * [[TensorFlow Lite]] | ||
| + | |||
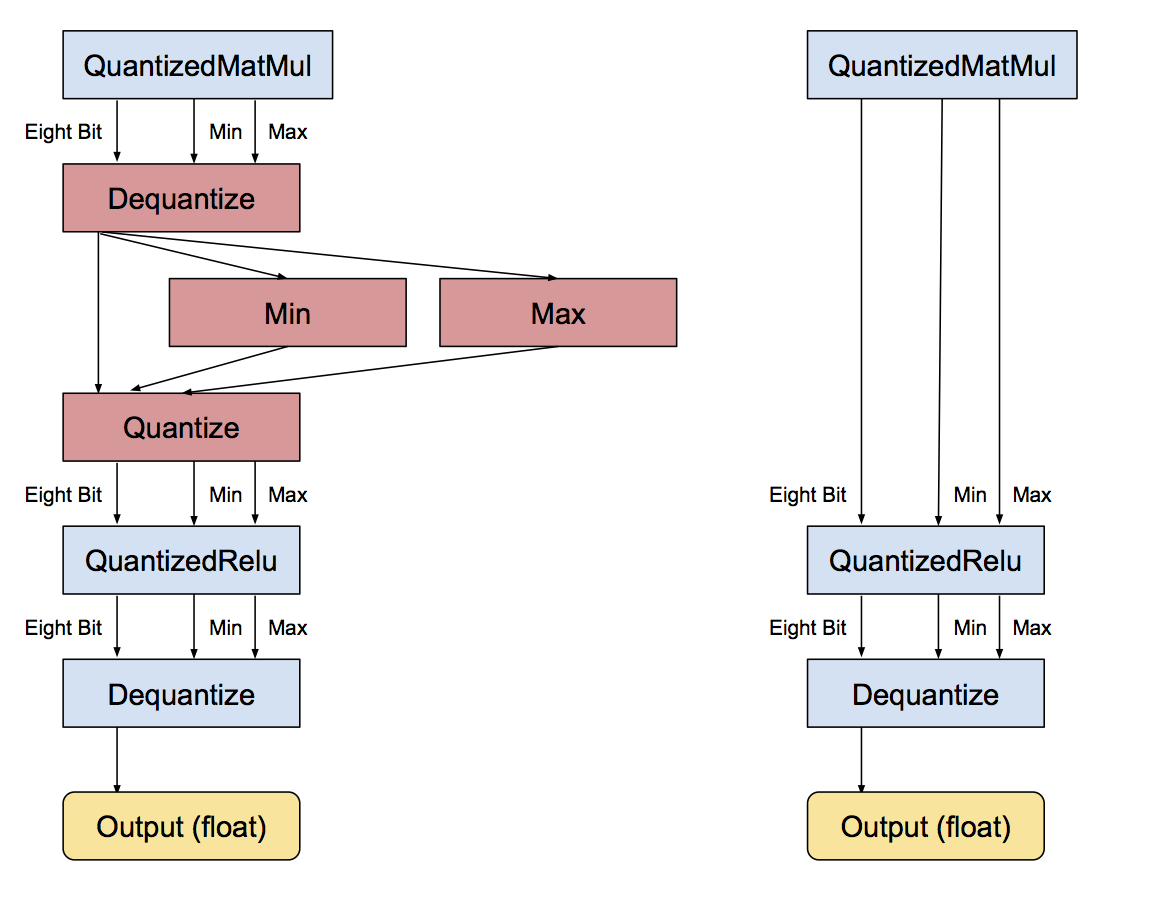
| + | the process of constraining an input from a continuous or otherwise large set of values (such as the real numbers) to a discrete set (such as the integers). An umbrella term that covers a lot of different techniques to store numbers and perform calculations on them in more compact formats than 32-bit floating point. | ||
| + | |||
| + | http://cdn-images-1.medium.com/max/800/0*lKwwM6_WSyBRkPCe.png | ||
| Line 26: | Line 35: | ||
<youtube>eZdOkDtYMoo</youtube> | <youtube>eZdOkDtYMoo</youtube> | ||
| + | |||
| + | http://petewarden.files.wordpress.com/2016/05/quantization2.png | ||
Revision as of 21:53, 2 March 2019
YouTube search... ...Google search
- How to Quantize Neural Networks with TensorFlow | Pete Warden
- 8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision | Manas Sahni
- TensorFlow Lite
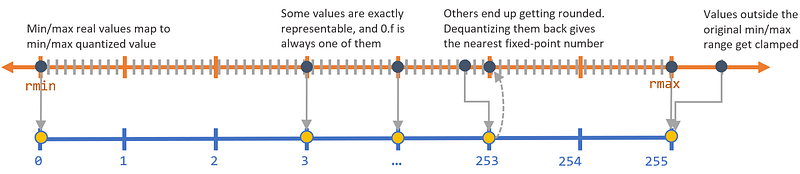
the process of constraining an input from a continuous or otherwise large set of values (such as the real numbers) to a discrete set (such as the integers). An umbrella term that covers a lot of different techniques to store numbers and perform calculations on them in more compact formats than 32-bit floating point.
Quantization-aware model training
ensures that the forward pass matches precision for both training and inference. There are two aspects to this:
- Operator fusion at inference time are accurately modeled at training time.
- Quantization effects at inference are modeled at training time.
For efficient inference, TensorFlow combines batch normalization with the preceding convolutional and fully-connected layers prior to quantization by folding batch norm layers.
Post-training quantization
is a general technique to reduce the model size while also providing up to 3x lower latency with little degradation in model accuracy. Post-training quantization quantizes weights to 8-bits of precision from floating-point.