Difference between revisions of "Word2Vec"
m |
m |
||
| Line 8: | Line 8: | ||
[http://www.google.com/search?q=Word2Vec+word+vectors+deep+machine+learning+ML+artificial+intelligence ...Google search] | [http://www.google.com/search?q=Word2Vec+word+vectors+deep+machine+learning+ML+artificial+intelligence ...Google search] | ||
| − | * [[Large Language Model (LLM)]] ... [[ | + | * [[Embedding]] ... [[Fine-tuning]] ... [[Retrieval-Augmented Generation (RAG)|RAG]] ... [[Agents#AI-Powered Search|Search]] ... [[Clustering]] ... [[Recommendation]] ... [[Anomaly Detection]] ... [[Classification]] ... [[Dimensional Reduction]]. [[...find outliers]] |
| + | * [[Large Language Model (LLM)]] ... [[Large Language Model (LLM)#Multimodal|Multimodal]] ... [[Foundation Models (FM)]] ... [[Generative Pre-trained Transformer (GPT)|Generative Pre-trained]] ... [[Transformer]] ... ([[GPT-4]]) ... [[GPT-5]] ... [[Attention]] ... [[Generative Adversarial Network (GAN)|GAN]] ... [[Bidirectional Encoder Representations from Transformers (BERT)|BERT]] | ||
* [[Doc2Vec]] | * [[Doc2Vec]] | ||
* [[Node2Vec]] | * [[Node2Vec]] | ||
Revision as of 01:29, 19 September 2023
Youtube search... ...Google search
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Large Language Model (LLM) ... Multimodal ... Foundation Models (FM) ... Generative Pre-trained ... Transformer ... (GPT-4) ... GPT-5 ... Attention ... GAN ... BERT
- Doc2Vec
- Node2Vec
- Skip-Gram
- Global Vectors for Word Representation (GloVe)
- Bag-of-Words (BoW)
- Continuous Bag-of-Words (CBoW)
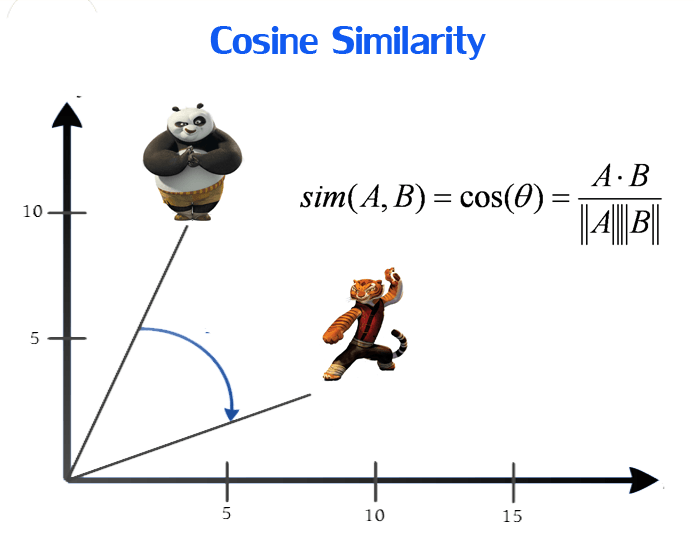
- Similarity
- TensorFlow
- Embedding ... Fine-tuning ... RAG ... Search ... Clustering ... Recommendation ... Anomaly Detection ... Classification ... Dimensional Reduction. ...find outliers
- Introduction to Word Embedding and Word2Vec | Dhruvil Karani - Towards Data Science - Medium
- Distributed Representations of Words and Phrases and their Compositionality | Tomas Mikolov - Google
a shallow, two-layer neural networks which is trained to reconstruct linguistic contexts of words. It takes as its input a large corpus of words and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space.