Difference between revisions of "Continuous Bag-of-Words (CBoW)"
m (Text replacement - "http:" to "https:") |
m |
||
| Line 9: | Line 9: | ||
* [[Bag-of-Words (BoW)]] | * [[Bag-of-Words (BoW)]] | ||
| − | * [[Natural Language Processing (NLP)]] | + | * [[Large Language Model (LLM)]] ... [[Natural Language Processing (NLP)]] ...[[Natural Language Generation (NLG)|Generation]] ... [[Natural Language Classification (NLC)|Classification]] ... [[Natural Language Processing (NLP)#Natural Language Understanding (NLU)|Understanding]] ... [[Language Translation|Translation]] ... [[Natural Language Tools & Services|Tools & Services]] |
* [[Word2Vec]] | * [[Word2Vec]] | ||
* [[Skip-Gram]] | * [[Skip-Gram]] | ||
Revision as of 15:57, 28 April 2023
YouTube search... ...Google search
- Bag-of-Words (BoW)
- Large Language Model (LLM) ... Natural Language Processing (NLP) ...Generation ... Classification ... Understanding ... Translation ... Tools & Services
- Word2Vec
- Skip-Gram
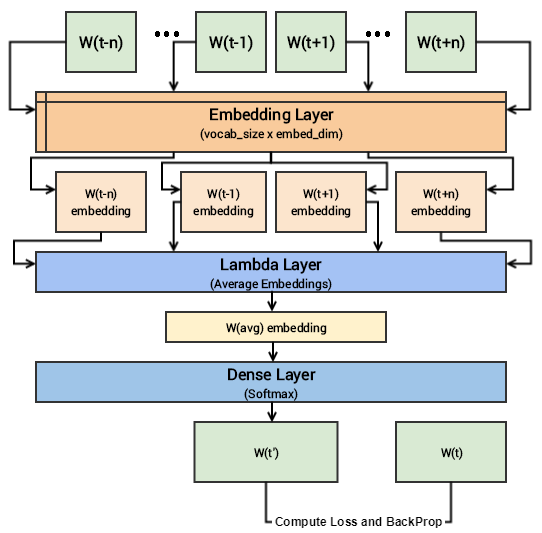
The CBOW model architecture tries to predict the current target word (the center word) based on the source context words (surrounding words). Considering a simple sentence, “the quick brown fox jumps over the lazy dog”, this can be pairs of (context_window, target_word) where if we consider a context window of size 2, we have examples like ([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy) and so on. Thus the model tries to predict the target_word based on the context_window words. A hands-on intuitive approach to Deep Learning Methods for Text Data — Word2Vec, GloVe and FastText | Dipanjan Sarkar - Towards Data Science