Difference between revisions of "Cross-Entropy Loss"
m |
|||
| Line 9: | Line 9: | ||
* [[Loss]] | * [[Loss]] | ||
| − | * [[ | + | * [[Algorithm Administration#Hyperparameter|Hyperparameter]] |
| + | |||
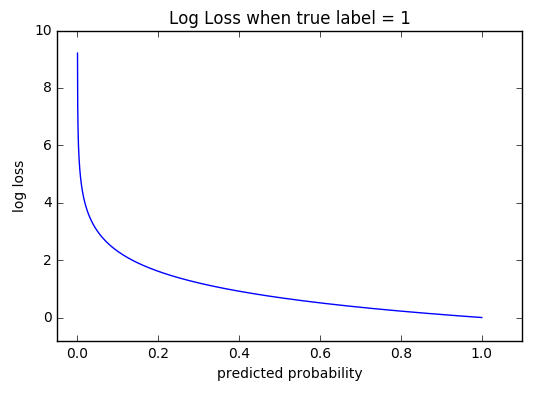
Cross-entropy [[loss]], or log [[loss]], measures the performance of a classification model whose output is a probability value between 0 and 1. Cross-entropy loss increases as the predicted probability diverges from the actual label. [http://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html | Cross-entropy [[loss]], or log [[loss]], measures the performance of a classification model whose output is a probability value between 0 and 1. Cross-entropy loss increases as the predicted probability diverges from the actual label. [http://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html | ||
Revision as of 15:36, 27 September 2020
YouTube search... ...Google search
Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1. Cross-entropy loss increases as the predicted probability diverges from the actual label. [http://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
Cross-entropy loss is one of the most widely used loss functions in classification scenarios. In face recognition tasks, the cross-entropy loss is an effective method to eliminate outliers. Neural Architecture Search for Deep Face Recognition | Ning Zhu