Difference between revisions of "(Stacked) Denoising Autoencoder (DAE)"
m (Text replacement - "http:" to "https:") |
|||
| (2 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
| − | [ | + | {{#seo: |
| + | |title=PRIMO.ai | ||
| + | |titlemode=append | ||
| + | |keywords=artificial, intelligence, machine, learning, models, algorithms, data, singularity, moonshot, Tensorflow, Google, Nvidia, Microsoft, Azure, Amazon, AWS | ||
| + | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | ||
| + | }} | ||
| + | [https://www.youtube.com/results?search_query=Stacked+Denoising+Autoencoder YouTube search...] | ||
| + | [https://www.google.com/search?q=Stacked+Denoising+Autoencoder+machine+learning+ML+artificial+intelligence ...Google search] | ||
| − | * [ | + | * [https://www.asimovinstitute.org/author/fjodorvanveen/ Neural Network Zoo | Fjodor Van Veen] |
| + | * [[Feature Exploration/Learning]] | ||
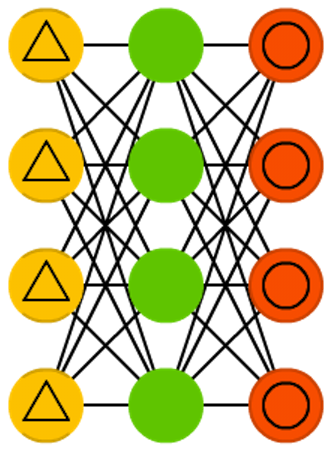
Denoising autoencoders (DAE) are AEs where we don’t feed just the input data, but we feed the input data with noise (like making an image more grainy). We compute the error the same way though, so the output of the network is compared to the original input without noise. This encourages the network not to learn details but broader features, as learning smaller features often turns out to be “wrong” due to it constantly changing with noise. Vincent, Pascal, et al. “Extracting and composing robust features with denoising autoencoders.” Proceedings of the 25th international conference on Machine learning. ACM, 2008. | Denoising autoencoders (DAE) are AEs where we don’t feed just the input data, but we feed the input data with noise (like making an image more grainy). We compute the error the same way though, so the output of the network is compared to the original input without noise. This encourages the network not to learn details but broader features, as learning smaller features often turns out to be “wrong” due to it constantly changing with noise. Vincent, Pascal, et al. “Extracting and composing robust features with denoising autoencoders.” Proceedings of the 25th international conference on Machine learning. ACM, 2008. | ||
| − | + | https://www.asimovinstitute.org/wp-content/uploads/2016/09/dae.png | |
<youtube>G1qA8z0PmR0</youtube> | <youtube>G1qA8z0PmR0</youtube> | ||
Latest revision as of 20:30, 27 March 2023
YouTube search... ...Google search
Denoising autoencoders (DAE) are AEs where we don’t feed just the input data, but we feed the input data with noise (like making an image more grainy). We compute the error the same way though, so the output of the network is compared to the original input without noise. This encourages the network not to learn details but broader features, as learning smaller features often turns out to be “wrong” due to it constantly changing with noise. Vincent, Pascal, et al. “Extracting and composing robust features with denoising autoencoders.” Proceedings of the 25th international conference on Machine learning. ACM, 2008.