Difference between revisions of "Quantization"
(Created page with "{{#seo: |title=PRIMO.ai |titlemode=append |keywords=artificial, intelligence, machine, learning, models, algorithms, data, singularity, moonshot, Tensorflow, Google, Nvidia, M...") |
|||
| (13 intermediate revisions by the same user not shown) | |||
| Line 5: | Line 5: | ||
|description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | |description=Helpful resources for your journey with artificial intelligence; videos, articles, techniques, courses, profiles, and tools | ||
}} | }} | ||
| − | [http://www.youtube.com/results?search_query= | + | [http://www.youtube.com/results?search_query=Quantization+aware+model+training YouTube search...] |
| − | [http://www.google.com/search?q= | + | [http://www.google.com/search?q=Quantization+aware+model+training ...Google search] |
| − | * [ | + | * [http://petewarden.com/2016/05/03/how-to-quantize-neural-networks-with-tensorflow/ How to Quantize Neural Networks with TensorFlow | Pete Warden] |
| + | * [http://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd 8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision | Manas Sahni] | ||
| − | <youtube> | + | |
| + | the process of constraining an input from a continuous or otherwise large set of values (such as the real numbers) to a discrete set (such as the integers). An umbrella term that covers a lot of different techniques to store numbers and perform calculations on them in more compact formats than 32-bit floating point. | ||
| + | |||
| + | http://cdn-images-1.medium.com/max/800/0*lKwwM6_WSyBRkPCe.png | ||
| + | |||
| + | |||
| + | For many deep learning problems, we’re finally getting to the “make it efficient” stage. We’d been stuck in the first two stages for many decades, where speed and efficiency weren’t nearly as important as getting things to work in the first place. So the question of how precise our calculations need to be — and whether we can manage with lower precision — wasn’t often asked. However, now that neural networks are good enough at many problems to be of production-grade or better, this question has arisen again. And the answers suggest we could do with low(er) precision, causing what may soon be a paradigm shift in mobile-optimized AI. Given this shift, this post explores the concept of quantized inference and how it works in [[TensorFlow Lite]]. | ||
| + | |||
| + | |||
| + | ===== Quantization-aware model training ===== | ||
| + | * [http://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/quantize#quantization-aware-training Quantization-aware training] | ||
| + | |||
| + | ensures that the forward pass matches precision for both training and inference. There are two aspects to this: | ||
| + | |||
| + | * Operator fusion at inference time are accurately modeled at training time. | ||
| + | * Quantization effects at inference are modeled at training time. | ||
| + | |||
| + | For efficient inference, [[TensorFlow]] combines batch normalization with the preceding convolutional and fully-connected layers prior to quantization by folding batch norm layers. | ||
| + | |||
| + | ===== Post-training quantization ===== | ||
| + | * [http://www.tensorflow.org/lite/performance/post_training_quantization Post-training quantization] | ||
| + | |||
| + | is a general technique to reduce the model size while also providing up to 3x lower latency with little degradation in model accuracy. Post-training quantization quantizes weights to 8-bits of precision from floating-point. | ||
| + | |||
| + | <youtube>eZdOkDtYMoo</youtube> | ||
| + | <youtube>vouEMwDNopQ</youtube> | ||
| + | |||
| + | http://petewarden.files.wordpress.com/2016/05/quantization2.png | ||
| + | |||
| + | * Pruning can remove lots of weights before doing quantization without hurting accuracy. Pruning can remove 67% for CONV layers, 90% for FC layers, verified across LeNet, AlexNet, VGGNet (shown in below paper), GoogLeNet, SqueezeNet, NeuralTalk (done recently after the paper) [http://arxiv.org/pdf/1506.02626v3.pdf Learning both Weights and Connections for Efficient Neural Networks] | ||
| + | |||
| + | * Combining with ‘Deep Compression’ even more compression ratio could be achieved by using mixed precision. (new results release in ICLR’16: GoogLeNet could be compressed by 10x; SqueezeNet could be compressed by 10x.) [http://arxiv.org/pdf/1510.00149.pdf DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING | Song Han, Huizi Mao, & William J. Dally] | ||
| + | |||
| + | * [http://songhan.github.io/SqueezeNet-Deep-Compression/ SqueezeNet: AlexNet-level accuracy with 50x fewer parameters | GitHub] | ||
Latest revision as of 22:30, 2 March 2019
YouTube search... ...Google search
- How to Quantize Neural Networks with TensorFlow | Pete Warden
- 8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision | Manas Sahni
the process of constraining an input from a continuous or otherwise large set of values (such as the real numbers) to a discrete set (such as the integers). An umbrella term that covers a lot of different techniques to store numbers and perform calculations on them in more compact formats than 32-bit floating point.
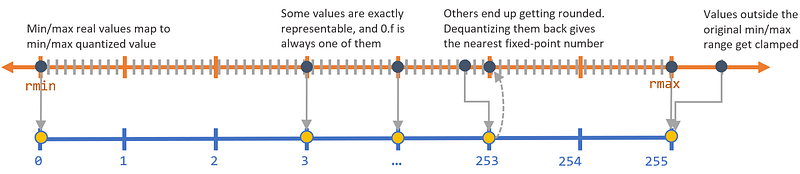
For many deep learning problems, we’re finally getting to the “make it efficient” stage. We’d been stuck in the first two stages for many decades, where speed and efficiency weren’t nearly as important as getting things to work in the first place. So the question of how precise our calculations need to be — and whether we can manage with lower precision — wasn’t often asked. However, now that neural networks are good enough at many problems to be of production-grade or better, this question has arisen again. And the answers suggest we could do with low(er) precision, causing what may soon be a paradigm shift in mobile-optimized AI. Given this shift, this post explores the concept of quantized inference and how it works in TensorFlow Lite.
Quantization-aware model training
ensures that the forward pass matches precision for both training and inference. There are two aspects to this:
- Operator fusion at inference time are accurately modeled at training time.
- Quantization effects at inference are modeled at training time.
For efficient inference, TensorFlow combines batch normalization with the preceding convolutional and fully-connected layers prior to quantization by folding batch norm layers.
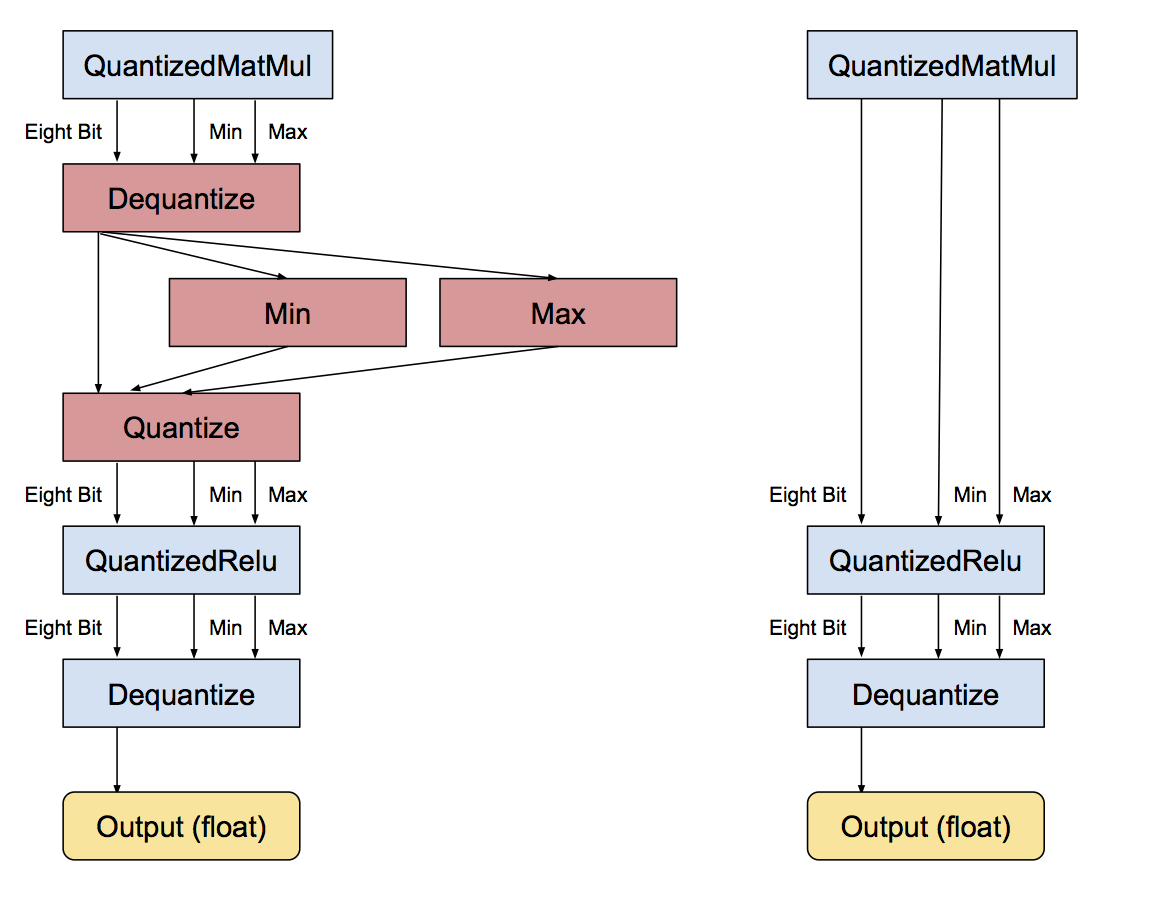
Post-training quantization
is a general technique to reduce the model size while also providing up to 3x lower latency with little degradation in model accuracy. Post-training quantization quantizes weights to 8-bits of precision from floating-point.
- Pruning can remove lots of weights before doing quantization without hurting accuracy. Pruning can remove 67% for CONV layers, 90% for FC layers, verified across LeNet, AlexNet, VGGNet (shown in below paper), GoogLeNet, SqueezeNet, NeuralTalk (done recently after the paper) Learning both Weights and Connections for Efficient Neural Networks
- Combining with ‘Deep Compression’ even more compression ratio could be achieved by using mixed precision. (new results release in ICLR’16: GoogLeNet could be compressed by 10x; SqueezeNet could be compressed by 10x.) DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING | Song Han, Huizi Mao, & William J. Dally