Difference between revisions of "Feed Forward Neural Network (FF or FFNN)"
m (BPeat moved page Feed Forward Neural Networks (FF or FFNN) to Feed Forward Neural Network (FF or FFNN) without leaving a redirect) |
|||
| Line 3: | Line 3: | ||
* [http://www.asimovinstitute.org/author/fjodorvanveen/ Neural Network Zoo | Fjodor Van Veen] | * [http://www.asimovinstitute.org/author/fjodorvanveen/ Neural Network Zoo | Fjodor Van Veen] | ||
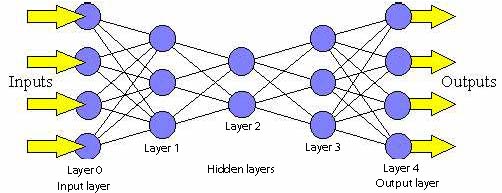
| − | Feed forward neural networks (FF or FFNN) and perceptrons (P) are very straight forward, they feed information from the front to the back (input and output, respectively). Neural networks are often described as having layers, where each layer consists of either input, hidden or output cells in parallel. A layer alone never has connections and in general two adjacent layers are fully connected (every neuron form one layer to every neuron to another layer). The simplest somewhat practical network has two input cells and one output cell, which can be used to model logic gates. One usually trains FFNNs through back-propagation, giving the network paired datasets of “what goes in” and “what we want to have coming out”. This is called supervised learning, as opposed to unsupervised learning where we only give it input and let the network fill in the blanks. The error being back-propagated is often some variation of the difference between the input and the output (like MSE or just the linear difference). Given that the network has enough hidden neurons, it can theoretically always model the relationship between the input and output. Practically their use is a lot more limited but they are popularly combined with other networks to form new networks. | + | Feed forward neural networks (FF or FFNN) and perceptrons (P) are very straight forward, they feed information from the front to the back (input and output, respectively). Neural networks are often described as having layers, where each layer consists of either input, hidden or output cells in parallel. A layer alone never has connections and in general two adjacent layers are fully connected (every neuron form one layer to every neuron to another layer). The simplest somewhat practical network has two input cells and one output cell, which can be used to model logic gates. One usually trains FFNNs through back-propagation, giving the network paired datasets of “what goes in” and “what we want to have coming out”. This is called supervised learning, as opposed to unsupervised learning where we only give it input and let the network fill in the blanks. The error being back-propagated is often some variation of the difference between the input and the output (like MSE or just the linear difference). Given that the network has enough hidden neurons, it can theoretically always model the relationship between the input and output. Practically their use is a lot more limited but they are popularly combined with other networks to form new networks. Rosenblatt, Frank. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review 65.6 (1958): 386. |
| − | Rosenblatt, Frank. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review 65.6 (1958): 386. | + | |
| + | https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/Architecture/images/feedforward.jpg | ||
<youtube>apPiZd-qnZ8</youtube> | <youtube>apPiZd-qnZ8</youtube> | ||
<youtube>qWK7yW8oS0I</youtube> | <youtube>qWK7yW8oS0I</youtube> | ||
Revision as of 22:54, 12 May 2018
Feed forward neural networks (FF or FFNN) and perceptrons (P) are very straight forward, they feed information from the front to the back (input and output, respectively). Neural networks are often described as having layers, where each layer consists of either input, hidden or output cells in parallel. A layer alone never has connections and in general two adjacent layers are fully connected (every neuron form one layer to every neuron to another layer). The simplest somewhat practical network has two input cells and one output cell, which can be used to model logic gates. One usually trains FFNNs through back-propagation, giving the network paired datasets of “what goes in” and “what we want to have coming out”. This is called supervised learning, as opposed to unsupervised learning where we only give it input and let the network fill in the blanks. The error being back-propagated is often some variation of the difference between the input and the output (like MSE or just the linear difference). Given that the network has enough hidden neurons, it can theoretically always model the relationship between the input and output. Practically their use is a lot more limited but they are popularly combined with other networks to form new networks. Rosenblatt, Frank. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review 65.6 (1958): 386.