Difference between revisions of "Dropout"
| Line 14: | Line 14: | ||
* add more data | * add more data | ||
* use [[Data Augmentation]] | * use [[Data Augmentation]] | ||
| − | * use [[Batch | + | * use [[Batch Norm(alization) & Standardization]] |
* use architectures that generalize well | * use architectures that generalize well | ||
* reduce architecture complexity | * reduce architecture complexity | ||
Revision as of 19:31, 2 January 2019
Youtube search... ...Google search
- Regularization
- Dropout Regularization in Deep Learning Models With Keras | Jason Brownlee - Machine Learning Mastery
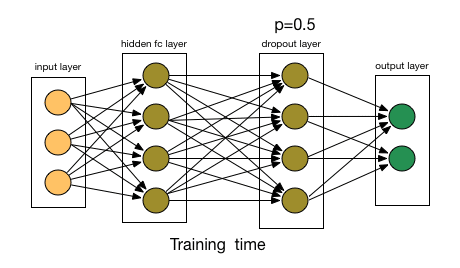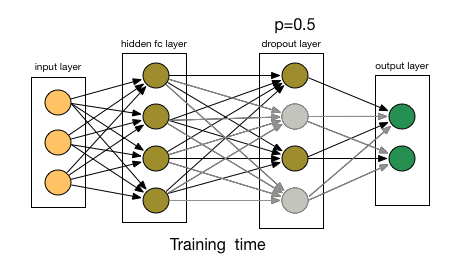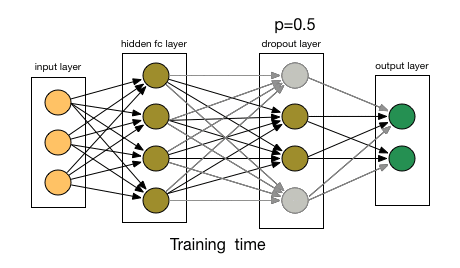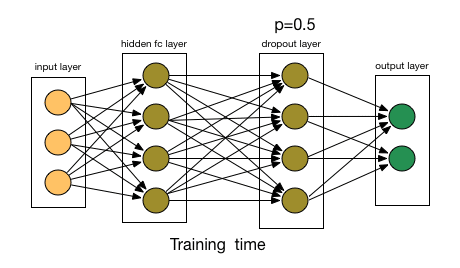
Deep neural nets with a large number of parameters are very powerful machine learning systems. However, overfitting is a serious problem in such networks. Large networks are also slow to use, making it difficult to deal with overfitting by combining the predictions of many different large neural nets at test time. Dropout is a technique for addressing this problem. The key idea is to randomly drop units (along with their connections) from the neural network during training. This prevents units from co-adapting too much. During training, dropout samples from an exponential number of different “thinned” networks. At test time, it is easy to approximate the effect of averaging the predictions of all these thinned networks by simply using a single unthinned network that has smaller weights. This significantly reduces overfitting and gives major improvements over other regularization methods.Dropout: A Simple Way to Prevent Neural Networks from Overfitting | Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov
Good practices for addressing the Overfitting Challenge:
- add more data
- use Data Augmentation
- use Batch Norm(alization) & Standardization
- use architectures that generalize well
- reduce architecture complexity
- add Regularization
- L1 and L2 Regularization - update the general cost function by adding another term known as the regularization term.
- Dropout - at every iteration, it randomly selects some nodes and temporarily removes the nodes (along with all of their incoming and outgoing connections)
- Data Augmentation
- Early Stopping