Difference between revisions of "RAPIDS"
| Line 1: | Line 1: | ||
| − | [http://www.youtube.com/results?search_query=RAPIDS+NVIDIA | + | [http://www.youtube.com/results?search_query=RAPIDS+NVIDIA Youtube search...] |
* [[NVIDIA]] | * [[NVIDIA]] | ||
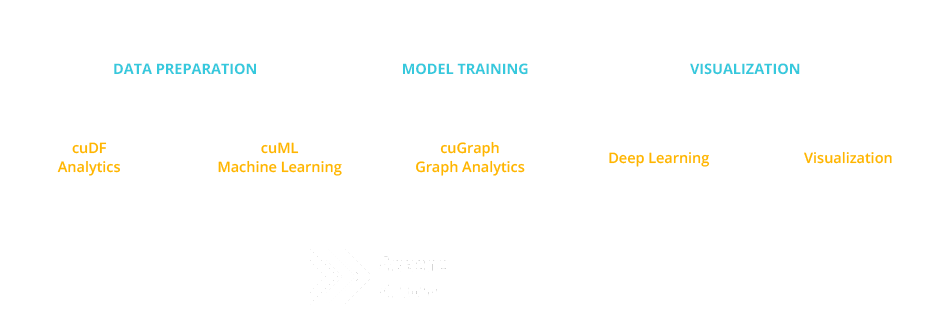
| − | The RAPIDS suite of open source software libraries gives you the freedom to execute end-to-end data science and analytics pipelines entirely on GPUs. It relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces. RAPIDS also focuses on common data preparation tasks for analytics and data science. This includes a familiar DataFrame API that integrates with a variety of machine learning algorithms for end-to-end pipeline accelerations without paying typical serialization costs. RAPIDS also includes support for multi-node, multi-GPU deployments, enabling vastly accelerated processing and training on much larger dataset sizes. [http://rapids.ai/ RAPIDS Getting Started | NVIDIA] | + | The RAPIDS data science framework includes a collection of libraries for executing end-to-end data science pipelines completely in the GPU. It is designed to have a familiar look and feel to data scientists working in Python. The RAPIDS suite of open source software libraries gives you the freedom to execute end-to-end data science and analytics pipelines entirely on GPUs. It relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces. RAPIDS also focuses on common data preparation tasks for analytics and data science. This includes a familiar DataFrame API that integrates with a variety of machine learning algorithms for end-to-end pipeline accelerations without paying typical serialization costs. RAPIDS also includes support for multi-node, multi-GPU deployments, enabling vastly accelerated processing and training on much larger dataset sizes. [http://rapids.ai/ RAPIDS Getting Started | NVIDIA] |
| − | <youtube> | + | http://rapids.ai/images/Pipeline-FPO-Diagram.png |
| − | <youtube> | + | |
| + | <youtube>nMLleQmphhU</youtube> | ||
| + | <youtube>G1kx_7NJJGA</youtube> | ||
Revision as of 21:40, 20 October 2018
The RAPIDS data science framework includes a collection of libraries for executing end-to-end data science pipelines completely in the GPU. It is designed to have a familiar look and feel to data scientists working in Python. The RAPIDS suite of open source software libraries gives you the freedom to execute end-to-end data science and analytics pipelines entirely on GPUs. It relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces. RAPIDS also focuses on common data preparation tasks for analytics and data science. This includes a familiar DataFrame API that integrates with a variety of machine learning algorithms for end-to-end pipeline accelerations without paying typical serialization costs. RAPIDS also includes support for multi-node, multi-GPU deployments, enabling vastly accelerated processing and training on much larger dataset sizes. RAPIDS Getting Started | NVIDIA