Difference between revisions of "(Deep) Convolutional Neural Network (DCNN/CNN)"
m |
m |
||
| Line 11: | Line 11: | ||
* [[Representation Learning]] | * [[Representation Learning]] | ||
* [http://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ An Intuitive Explanation of Convolutional Neural Networks | ujjwalkarn] | * [http://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ An Intuitive Explanation of Convolutional Neural Networks | ujjwalkarn] | ||
| − | * [[ | + | * [[Vision]] |
* [[Style Transfer]] | * [[Style Transfer]] | ||
* [http://www.asimovinstitute.org/author/fjodorvanveen/ Neural Network Zoo | Fjodor Van Veen] | * [http://www.asimovinstitute.org/author/fjodorvanveen/ Neural Network Zoo | Fjodor Van Veen] | ||
Revision as of 09:43, 26 March 2023
YouTube search... ...Google search
- Deep Learning
- Representation Learning
- An Intuitive Explanation of Convolutional Neural Networks | ujjwalkarn
- Vision
- Style Transfer
- Neural Network Zoo | Fjodor Van Veen
- Guide
- CNN1. What is Computer Vision? | deeplearning.ai
- Convolutional Neural Networks for Visual Recognition | Stanford
- Learning AI if You Suck at Math — P5 — Deep Learning and Convolutional Neural Nets in Plain English! | Daniel Jeffries
- Graph Convolutional Network (GCN), Graph Neural Networks (Graph Nets), Geometric Deep Learning
- Foundations Built for a General Theory of Neural Networks | Kevin Hartnett
- CaImAn an open source tool for scalable calcium imaging data analysis | A. Giovannucci, J. Friedrich, P. Gunn, J. Kalfon, B. Brown, S. Koay, J. Taxidis, F. Najafi, J. Gauthier, P. Zhou, B. Khakh, D. Tank, D. Chklovskii, and E. Pnevmatikakis-eLIFE
- Convolutional Neural Networks: A Python Tutorial Using TensorFlow and Keras | Luciano Strika - MercadoLibre - KDnuggests
- A Beginner's Guide to Convolutional Neural Networks (CNNs) | Chris Nicholson - A.I. Wiki pathmind
- LeNet-5, convolutional neural networks | Yann LeCun
- Basic Convolutional Neural Network Architectures | Anomi Ragendran - DZone
Convolution - is an integral that expresses the amount of overlap of one function g as it is shifted over another function f. It therefore "blends" one function with another.{Wolfram} a mathematical operation on two functions (f and g) to produce a third function that expresses how the shape of one is modified by the other. The term convolution refers to both the result function and to the process of computing it. Convolution is similar to cross-correlation. | Wikipedia
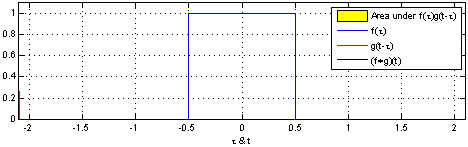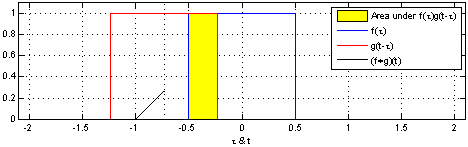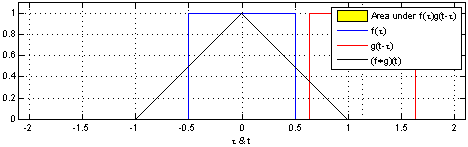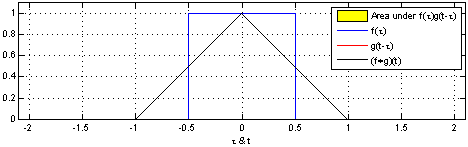

Convolutional Neural Networks (ConvNets or CNNs) classify images (e.g. name what they see), cluster them by similarity (photo search), and perform object recognition within scenes. They are algorithms that can identify faces, individuals, street signs, tumors, platypuses and many other aspects of visual data. Convolutional networks perform optical character recognition (OCR) to digitize text and make natural-language processing possible on analog and hand-written documents, where the images are symbols to be transcribed. CNNs can also be applied to sound when it is represented visually as a spectrogram. More recently, convolutional networks have been applied directly to text analytics as well as graph data with graph convolutional networks. They are primarily used for image processing but can also be used for other types of input such as as audio. A typical use case for CNNs is where you feed the network images and the network classifies the data, e.g. it outputs “cat” if you give it a cat picture and “dog” when you give it a dog picture. CNNs tend to start with an input “scanner” which is not intended to parse all the training data at once. For example, to input an image of 200 x 200 pixels, you wouldn’t want a layer with 40 000 nodes. Rather, you create a scanning input layer of say 20 x 20 which you feed the first 20 x 20 pixels of the image (usually starting in the upper left corner). Once you passed that input (and possibly use it for training) you feed it the next 20 x 20 pixels: you move the scanner one pixel to the right. Note that one wouldn’t move the input 20 pixels (or whatever scanner width) over, you’re not dissecting the image into blocks of 20 x 20, but rather you’re crawling over it. This input data is then fed through convolutional layers instead of normal layers, where not all nodes are connected to all nodes. Each node only concerns itself with close neighbouring cells (how close depends on the implementation, but usually not more than a few). These convolutional layers also tend to shrink as they become deeper, mostly by easily divisible factors of the input (so 20 would probably go to a layer of 10 followed by a layer of 5). Powers of two are very commonly used here, as they can be divided cleanly and completely by definition: 32, 16, 8, 4, 2, 1. Besides these convolutional layers, they also often feature pooling layers (Pooling / Sub-sampling: Max, Mean). Pooling is a way to filter out details: a commonly found pooling technique is max pooling, where we take say 2 x 2 pixels and pass on the pixel with the most amount of red. To apply CNNs for audio, you basically feed the input audio waves and inch over the length of the clip, segment by segment. Real world implementations of CNNs often glue an FFNN to the end to further process the data, which allows for highly non-linear abstractions. These networks are called DCNNs but the names and abbreviations between these two are often used interchangeably. LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.

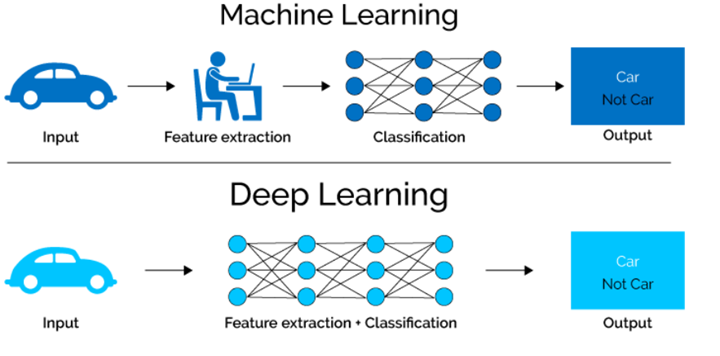
CNN Architectures
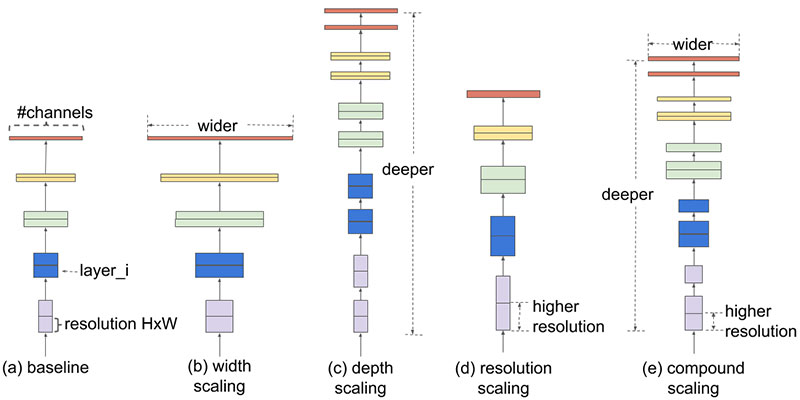
Compound Scaling
The researchers from the Google Research Brain Team demonstrated that there is an optimal ratio of depth, width, and resolution in order to maximize efficiency and accuracy. This is called compound scaling. The result is that EfficientNet’s performance surpasses the accuracy of other CNNs on ImageNet by up to 6% while being up to ten times more efficient in terms of speed and size.
DensePose