Difference between revisions of "(Boosted) Decision Tree"
| Line 4: | Line 4: | ||
** [[...predict categories]] | ** [[...predict categories]] | ||
* [[Capabilities]] | * [[Capabilities]] | ||
| + | * [http://xgboost.readthedocs.io/en/latest/model.html Introduction to Boosted Trees | XGBoost] | ||
* [http://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/two-class-boosted-decision-tree Two-Class Boosted Decision Tree | Microsoft] | * [http://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/two-class-boosted-decision-tree Two-Class Boosted Decision Tree | Microsoft] | ||
A boosted decision tree is an ensemble learning method in which the second tree corrects for the errors of the first tree, the third tree corrects for the errors of the first and second trees, and so forth. Predictions are based on the entire ensemble of trees together that makes the prediction. For further technical details, see the Research section of this article. Generally, when properly configured, boosted decision trees are the easiest methods with which to get top performance on a wide variety of machine learning tasks. However, they are also one of the more memory-intensive learners, and the current implementation holds everything in memory. Therefore, a boosted decision tree model might not be able to process the very large datasets that some linear learners can handle. | A boosted decision tree is an ensemble learning method in which the second tree corrects for the errors of the first tree, the third tree corrects for the errors of the first and second trees, and so forth. Predictions are based on the entire ensemble of trees together that makes the prediction. For further technical details, see the Research section of this article. Generally, when properly configured, boosted decision trees are the easiest methods with which to get top performance on a wide variety of machine learning tasks. However, they are also one of the more memory-intensive learners, and the current implementation holds everything in memory. Therefore, a boosted decision tree model might not be able to process the very large datasets that some linear learners can handle. | ||
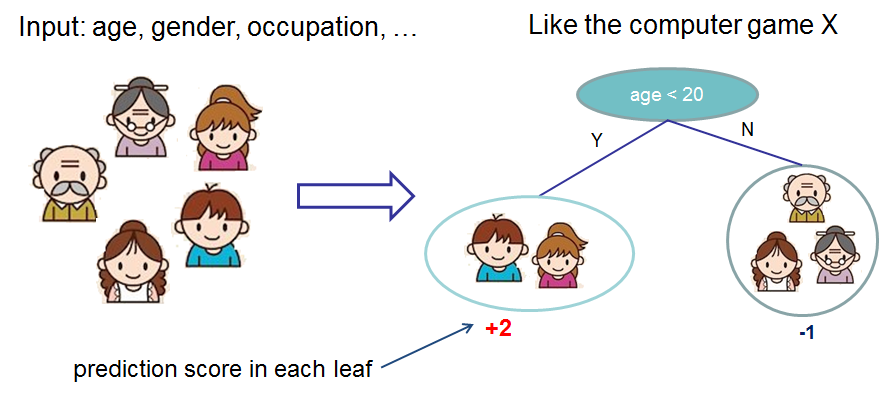
| − | + | http://raw.githubusercontent.com/dmlc/web-data/master/xgboost/model/cart.png | |
<youtube>mzcS_UT-UQ0</youtube> | <youtube>mzcS_UT-UQ0</youtube> | ||
| + | <youtube>0Xc9LIb_HTw</youtube> | ||
| + | <youtube>BXrrBWnuKlc</youtube> | ||
| + | <youtube>gehNcYRXs4M</youtube> | ||
Revision as of 22:15, 2 June 2018
- AI Solver
- Capabilities
- Introduction to Boosted Trees | XGBoost
- Two-Class Boosted Decision Tree | Microsoft
A boosted decision tree is an ensemble learning method in which the second tree corrects for the errors of the first tree, the third tree corrects for the errors of the first and second trees, and so forth. Predictions are based on the entire ensemble of trees together that makes the prediction. For further technical details, see the Research section of this article. Generally, when properly configured, boosted decision trees are the easiest methods with which to get top performance on a wide variety of machine learning tasks. However, they are also one of the more memory-intensive learners, and the current implementation holds everything in memory. Therefore, a boosted decision tree model might not be able to process the very large datasets that some linear learners can handle.