Difference between revisions of "Mean-Shift Clustering"
(Created page with "* AI Solver * ...cluster * ...no, I do not know the amount of groups/classes") |
|||
| Line 1: | Line 1: | ||
| + | [http://www.youtube.com/results?search_query=Mean+Shift+Clustering Youtube search...] | ||
| + | |||
* [[AI Solver]] | * [[AI Solver]] | ||
* [[...cluster]] | * [[...cluster]] | ||
* [[...no, I do not know the amount of groups/classes]] | * [[...no, I do not know the amount of groups/classes]] | ||
| + | |||
| + | Mean shift clustering is a sliding-window-based algorithm that attempts to find dense areas of data points. It is a centroid-based algorithm meaning that the goal is to locate the center points of each group/class, which works by updating candidates for center points to be the mean of the points within the sliding-window. These candidate windows are then filtered in a post-processing stage to eliminate near-duplicates, forming the final set of center points and their corresponding groups. [http://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68 The 5 Clustering Algorithms Data Scientists Need to Know | Towards Data Science] | ||
| + | |||
| + | http://cdn-images-1.medium.com/max/640/1*bkFlVrrm4HACGfUzeBnErw.gif | ||
| + | |||
| + | An illustration of the entire process from end-to-end with all of the sliding windows is show below. Each black dot represents the centroid of a sliding window and each gray dot is a data point. | ||
| + | |||
| + | https://cdn-images-1.medium.com/max/640/1*vyz94J_76dsVToaa4VG1Zg.gif | ||
| + | |||
| + | In contrast to K-means clustering there is no need to select the number of clusters as mean-shift automatically discovers this. That’s a massive advantage. The fact that the cluster centers converge towards the points of maximum density is also quite desirable as it is quite intuitive to understand and fits well in a naturally data-driven sense. The drawback is that the selection of the window size/radius “r” can be non-trivial. | ||
| + | |||
| + | <youtube>AIZ-YqZDOkI</youtube> | ||
| + | <youtube>5E097ZLE9Sg</youtube> | ||
| + | <youtube>SSFd6UHjxII</youtube> | ||
| + | <youtube>a69-jHtawEo</youtube> | ||
Revision as of 21:06, 30 May 2018
Mean shift clustering is a sliding-window-based algorithm that attempts to find dense areas of data points. It is a centroid-based algorithm meaning that the goal is to locate the center points of each group/class, which works by updating candidates for center points to be the mean of the points within the sliding-window. These candidate windows are then filtered in a post-processing stage to eliminate near-duplicates, forming the final set of center points and their corresponding groups. The 5 Clustering Algorithms Data Scientists Need to Know | Towards Data Science
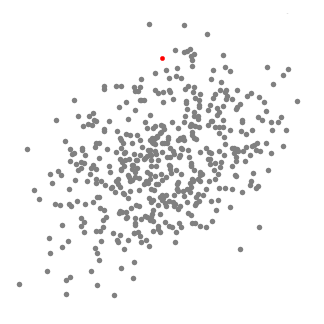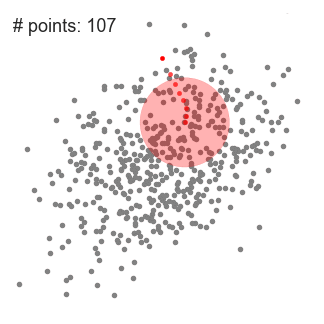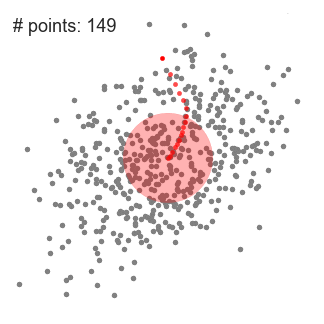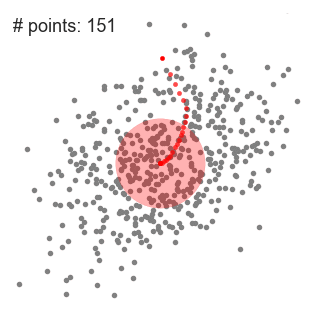
An illustration of the entire process from end-to-end with all of the sliding windows is show below. Each black dot represents the centroid of a sliding window and each gray dot is a data point.

In contrast to K-means clustering there is no need to select the number of clusters as mean-shift automatically discovers this. That’s a massive advantage. The fact that the cluster centers converge towards the points of maximum density is also quite desirable as it is quite intuitive to understand and fits well in a naturally data-driven sense. The drawback is that the selection of the window size/radius “r” can be non-trivial.