Difference between revisions of "Data Science"
m |
m |
||
| Line 54: | Line 54: | ||
{| class="wikitable" style="width: 550px;" | {| class="wikitable" style="width: 550px;" | ||
|| | || | ||
| − | <youtube> | + | <youtube>r-uOLxNrNk8</youtube> |
| − | <b>Data | + | <b>Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn) |
| − | </b><br> | + | </b><br>Learn Data Analysis with Python in this comprehensive tutorial for beginners, with exercises included! Data Analysis has been around for a long time, but up until a few years ago, it was practiced using closed, expensive and limited tools like Excel or Tableau. Python, SQL and other open libraries have changed Data Analysis forever. In this tutorial you'll learn the whole process of Data Analysis: reading data from multiple sources (CSVs, SQL, Excel, etc), processing them using NumPy and Pandas, visualize them using Matplotlib and Seaborn and clean and process it to create reports. Additionally, we've included a thorough Jupyter Notebook tutorial, and a quick Python reference to refresh your programming skills. Check out all Data Science courses from RMOTR: https://rmotr.com |
| − | |||
| − | |||
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
| Line 73: | Line 71: | ||
{| class="wikitable" style="width: 550px;" | {| class="wikitable" style="width: 550px;" | ||
|| | || | ||
| − | <youtube> | + | <youtube>D0B1JZMCMLo</youtube> |
| − | <b>Data | + | <b>Data Science in 30 Minutes: Predicting Content Demand with Machine Learning |
| − | </b><br> | + | </b><br>Netflix is well-known for its data-driven recommendations that seek to customize the user experience for every subscriber. But data science at Netflix extends far beyond that - from optimizing streaming and content caching to informing decisions about the TV shows and films available on the service. The talk covered work done by Becky and the Content Data Science team at Netflix, which seeks to evaluate where Netflix should spend their next content dollar using machine learning and predictive models. The Data Incubator is a data science education company based in NYC, DC, and SF with both corporate training as well as recruiting services. For data science corporate training, we offer customized, in-house corporate training solutions in data and analytics. For data science hiring, we run a free 8 week fellowship training PhDs to become data scientists. The fellowship selects 2% of its 2000+ quarterly applicants and is free for Fellows. Hiring companies (including EBay, Capital One, Pfizer) pay a recruiting fee only if they successfully hire. You can read about us on Harvard Business Review, VentureBeat, or The Next Web, or read about our alumni at LinkedIn, Palantir or the NYTimes. About the speakers: |
| + | Dr. Becky Tucker is a Senior Data Scientist at Netflix, a streaming media and entertainment company based in Los Gatos, CA. She holds a PhD in Physics from Caltech. At Netflix, Becky works on models that predict the demand for TV shows and movies. | ||
| + | Michael Li founded The Data Incubator, a New York-based training program that turns talented PhDs from academia into workplace-ready data scientists and quants. The program is free to Fellows, employers engage with the Incubator as hiring partners. | ||
|} | |} | ||
|}<!-- B --> | |}<!-- B --> | ||
Revision as of 09:39, 7 September 2020
YouTube search... ...Google search
- What is AI?
- AI Governance
- Data Science | Wikipedia
- Data science concepts you need to know! Part 1 | Michael Barber - Towards Data Science
- Data Fallacies to Avoid - An Illustrated Collection of Mistakes People Often Make When Analyzing Data - Tom Bransby
|
|
|
|
|
|
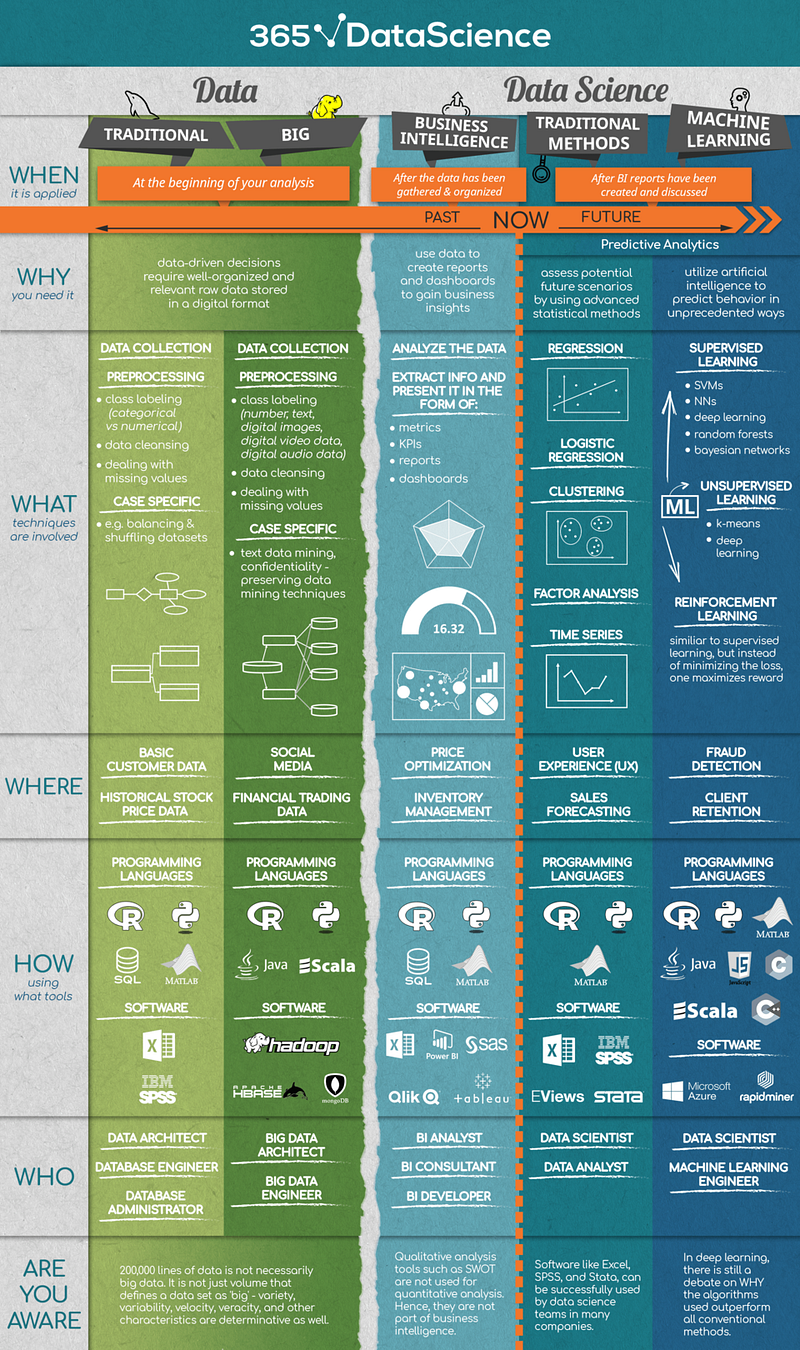
The What, Where and How of Data Science | Iliya Valchanov