Difference between revisions of "3D Model"
(→MVCNN) |
(→O-CNN) |
||
| Line 70: | Line 70: | ||
http://vis-www.cs.umass.edu/mvcnn/images/mvcnn.png | http://vis-www.cs.umass.edu/mvcnn/images/mvcnn.png | ||
| − | == | + | == Quadtrees and Octrees == |
[http://www.youtube.com/results?search_query=O-CNN+3D+artificial+intelligence+deep+learning+deep+machine+learning+ML+AI Youtube search...] | [http://www.youtube.com/results?search_query=O-CNN+3D+artificial+intelligence+deep+learning+deep+machine+learning+ML+AI Youtube search...] | ||
[http://www.google.com/search?q=O-CNN+3D+artificial+intelligence+deep+learning+deep+machine+learning+ML+AI ...Google search] | [http://www.google.com/search?q=O-CNN+3D+artificial+intelligence+deep+learning+deep+machine+learning+ML+AI ...Google search] | ||
* [http://arxiv.org/pdf/1712.01537.pdf O-CNN: Octree-based convolutional neural networks for 3D shape analysis | P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong] | * [http://arxiv.org/pdf/1712.01537.pdf O-CNN: Octree-based convolutional neural networks for 3D shape analysis | P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong] | ||
| − | ** [http://github.com/microsoft/O-CNN O-CNN | P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong | GitHub] repository contains the implementation of O-CNN and Aadptive O-CNN | + | ** [http://github.com/microsoft/O-CNN O-CNN | P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong | GitHub] repository contains the implementation of O-CNN and Aadptive O-CNN ...built upon the Caffe framework and it supports octree-based convolution, deconvolution, pooling, and unpooling. |
| − | + | * [http://arxiv.org/abs/1611.05009 OctNet: Learning Deep 3D Representations at High Resolutions] a representation for deep learning with sparse 3D data. In contrast to existing models, our representation enables 3D convolutional networks which are both deep and high resolution. Towards this goal, we exploit the sparsity in the input data to hierarchically partition the space using a set of unbalanced octrees where each leaf node stores a pooled feature representation. This allows to focus memory allocation and computation to the relevant dense regions and enables deeper networks without compromising resolution. | |
| − | |||
<youtube>8jfAqRzAudw</youtube> | <youtube>8jfAqRzAudw</youtube> | ||
| + | <youtube>qYyephF2BBw</youtube> | ||
== LiDAR == | == LiDAR == | ||
Revision as of 16:56, 28 July 2019
Youtube search... ...Google search
- Capabilities
- Point Cloud
- Screening; Passenger & Luggage
- Spatial-Temporal Dynamic Network (STDN)
- 3D Simulation Environments
- A survey on Deep Learning Advances on Different 3D Data Representations | E. Ahmed, A. Saint, A. Shabayek, K. Cherenkova, R. Das, G. Gusev, and D. Aouada - extending 2D deep learning to 3D data is not a straightforward tasks depending on the data representation itself and the task at hand.
- VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition | Daniel Maturana and Sebastian Scherer
Contents
Geometric Deep Learning
3D Machine Learning | GitHub
- Courses
- Datasets
- 3D Pose Estimation
- Single Object Classification
- Multiple Objects Detection
- Scene/Object Semantic Segmentation
- 3D Geometry Synthesis/Reconstruction
- Texture/Material Analysis and Synthesis
- Style Learning and Transfer
- Scene Synthesis/Reconstruction
- Scene Understanding
3D Models from 2D Images
3DCNN
Youtube search... ...Google search
Schematic diagram of the Deep 3D Convolutional Neural Network and FEATURE-Softmax Classifier models. a Deep 3D Convolutional Neural Network. The feature extraction stage includes 3D convolutional and Pooling / Sub-sampling: Max, Mean layers. 3D filters in the 3D convolutional layers search for recurrent spatial patterns that best capture the local biochemical features to separate the 20 amino acid microenvironments. Pooling / Sub-sampling: Max, Mean layers perform down-sampling to the input to increase translational invariances of the network. By following the 3DCNN and 3D Pooling / Sub-sampling: Max, Mean layers with fully connected layers, the pooled filter responses of all filters across all positions in the protein box can be integrated. The integrated information is then fed to the Softmax classifier layer to calculate class probabilities and to make the final predictions. Prediction error drives parameter updates of the trainable parameters in the classifier, fully connected layers, and convolutional filters to learn the best feature for the optimal performances. b The FEATURE Softmax Classifier. The FEATURE Softmax model begins with an input layer, which takes in FEATURE vectors, followed by two fully-connected layers, and ends with a Softmax classifier layer. In this case, the input layer is equivalent to the feature extraction stage. In contrast to 3DCNN, the prediction error only drives parameter learning of the fully connected layers and classifier. The input feature is fixed during the whole training process

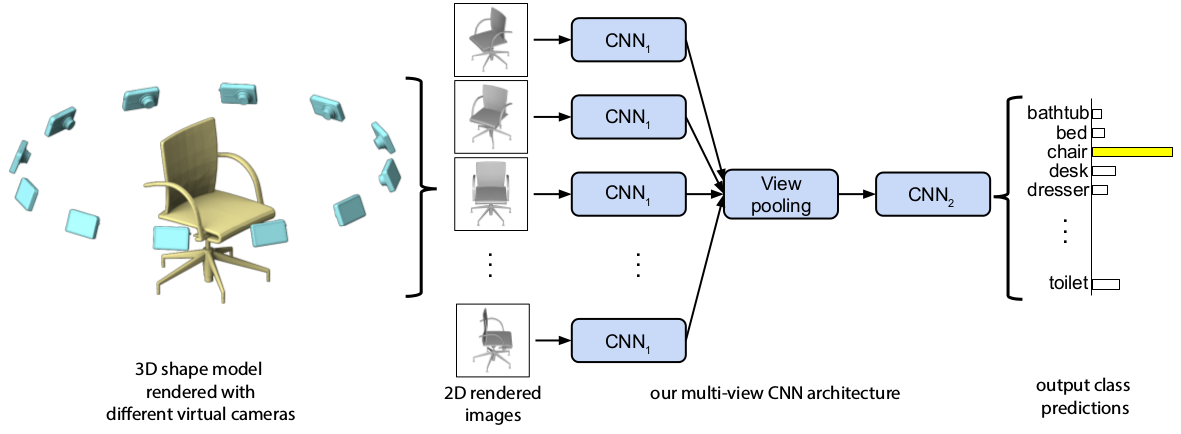
MVCNN
Youtube search... ...Google search
A longstanding question in computer vision concerns the representation of 3D shapes for recognition: should 3D shapes be represented with descriptors operating on their native 3D formats, such as voxel grid or polygon mesh, or can they be effectively represented with view-based descriptors? We address this question in the context of learning to recognize 3D shapes from a collection of their rendered views on 2D images. We first present a standard CNN architecture trained to recognize the shapes’ rendered views independently of each other, and show that a 3D shape can be recognized even from a single view at an accuracy far higher than using state-of-the-art 3D shape descriptors. Recognition rates further increase when multiple views of the shapes are provided. In addition, we present a novel CNN architecture that combines information from multiple views of a 3D shape into a single and compact shape descriptor offering even better recognition performance. The same architecture can be applied to accurately recognize human hand-drawn sketches of shapes. We conclude that a collection of 2D views can be highly informative for 3D shape recognition and is amenable to emerging CNN architectures and their derivatives. Multi-view Convolutional Neural Networks for 3D Shape Recognition H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller and MVCNN with PyTorch
Quadtrees and Octrees
Youtube search... ...Google search
- O-CNN: Octree-based convolutional neural networks for 3D shape analysis | P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong
- O-CNN | P. Wang, Y. Liu, Y. Guo, C. Sun, and X. Tong | GitHub repository contains the implementation of O-CNN and Aadptive O-CNN ...built upon the Caffe framework and it supports octree-based convolution, deconvolution, pooling, and unpooling.
- OctNet: Learning Deep 3D Representations at High Resolutions a representation for deep learning with sparse 3D data. In contrast to existing models, our representation enables 3D convolutional networks which are both deep and high resolution. Towards this goal, we exploit the sparsity in the input data to hierarchically partition the space using a set of unbalanced octrees where each leaf node stores a pooled feature representation. This allows to focus memory allocation and computation to the relevant dense regions and enables deeper networks without compromising resolution.
LiDAR
Youtube search... ...Google search
LiDAR involves firing rapid laser pulses at objects and measuring how much time they take to return to the sensor. This is similar to the "time of flight" technology for RGB-D cameras we described above, but LiDAR has significantly longer range, captures many more points, and is much more robust to interference from other light sources. Most 3D LiDAR sensors today have several (up to 64) beams aligned vertically, spinning rapidly to see in all directions around the sensor. These are the sensors used in most self-driving cars because of their accuracy, range, and robustness, but the problem with LiDAR sensors is that they're often large, heavy, and extremely expensive (the 64-beam sensor that most self-driving cars use costs $75,000!). As a result, many companies are currently trying to develop cheaper “solid state LiDAR” systems that can sense in 3D without having to spin. Beyond the pixel plane: sensing and learning in 3D | Mihir Garimella, Prathik Naidu - Stanford

3D Printing