Difference between revisions of "...cluster"
m |
|||
| (3 intermediate revisions by the same user not shown) | |||
| Line 19: | Line 19: | ||
___________________________________________________ | ___________________________________________________ | ||
| − | |||
* [[Clustering]] | * [[Clustering]] | ||
| − | * [ | + | * [https://www.clusteranalysis4marketing.com Quick Cluster Analysis for Excel] |
| − | * [ | + | ** [[Excel]] ... [[LangChain#Documents|Documents]] ... [[Database|Database; Vector & Relational]] ... [[Graph]] ... [[LlamaIndex]] |
| − | * [ | + | * [https://www.kdnuggets.com/2019/10/right-clustering-algorithm.html Choosing the Right Clustering Algorithm for your Dataset | josh Thompson - KDnuggets] |
| − | * [ | + | * [https://www.kdnuggets.com/2018/06/5-clustering-algorithms-data-scientists-need-know.html The 5 Clustering Algorithms Data Scientists Need to Know | George Seif - KDnuggets] |
| + | * [https://medium.com/@srnghn/machine-learning-trying-to-discover-structure-in-your-data-2fbbc4f819ae Machine Learning: Trying to discover structure in your data | Stacey Ronaghan - Medium] | ||
| − | Given a set of data points, we can use a clustering algorithm to classify each data point into a specific group. In theory, data points that are in the same group should have similar properties and/or features, while data points in different groups should have highly dissimilar properties and/or features. Clustering is a method of unsupervised learning and is a common technique for statistical data analysis used in many fields. We can use clustering analysis to gain some valuable insights from our data by seeing what groups the data points fall into when we apply a clustering algorithm. [ | + | Given a set of data points, we can use a clustering algorithm to classify each data point into a specific group. In theory, data points that are in the same group should have similar properties and/or features, while data points in different groups should have highly dissimilar properties and/or features. Clustering is a method of unsupervised learning and is a common technique for statistical data analysis used in many fields. We can use clustering analysis to gain some valuable insights from our data by seeing what groups the data points fall into when we apply a clustering algorithm. [https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68 The 5 Clustering Algorithms Data Scientists Need to Know] |
=== [[K-Means]] Clustering === | === [[K-Means]] Clustering === | ||
| − | + | https://cdn-images-1.medium.com/max/800/1*KrcZK0xYgTa4qFrVr0fO2w.gif | |
=== [[Mean-Shift Clustering]] === | === [[Mean-Shift Clustering]] === | ||
| − | + | https://cdn-images-1.medium.com/max/800/1*vyz94J_76dsVToaa4VG1Zg.gif | |
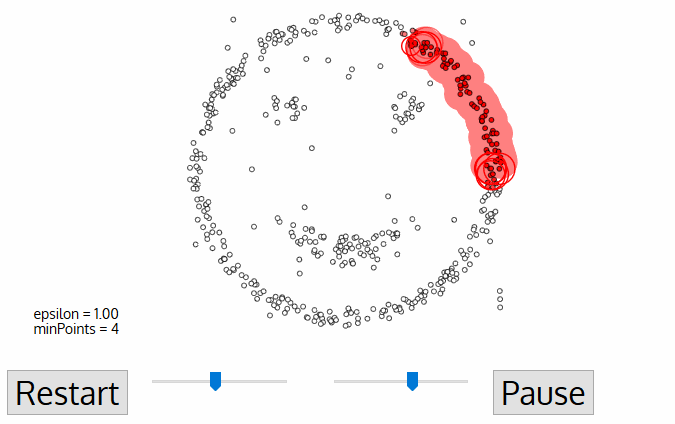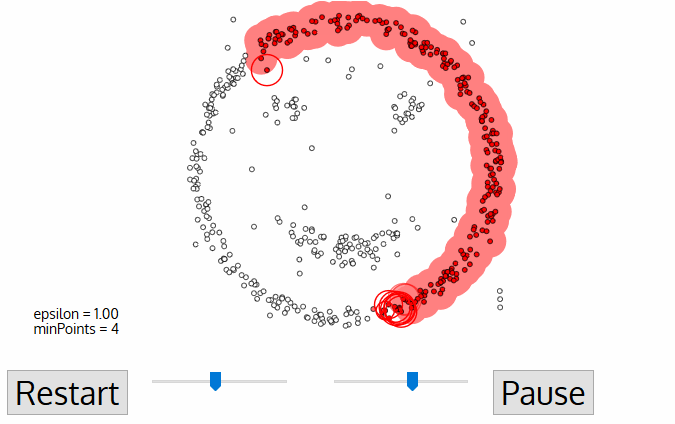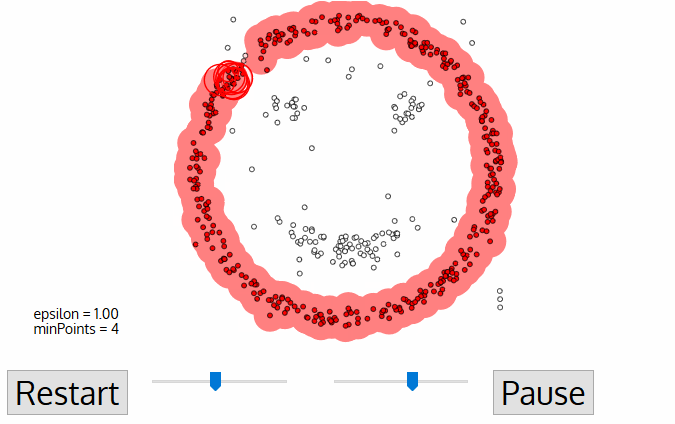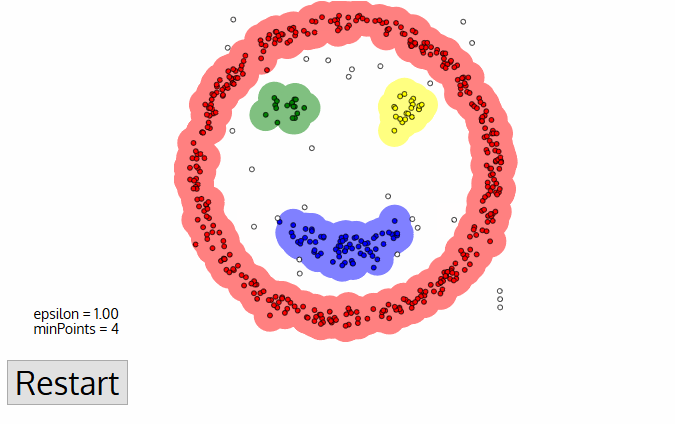
=== [[Density-Based Spatial Clustering of Applications with Noise (DBSCAN)]] === | === [[Density-Based Spatial Clustering of Applications with Noise (DBSCAN)]] === | ||
| − | + | https://cdn-images-1.medium.com/max/800/1*tc8UF-h0nQqUfLC8-0uInQ.gif | |
=== [[Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM)]] === | === [[Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM)]] === | ||
| − | + | https://cdn-images-1.medium.com/max/800/1*OyXgise21a23D5JCss8Tlg.gif | |
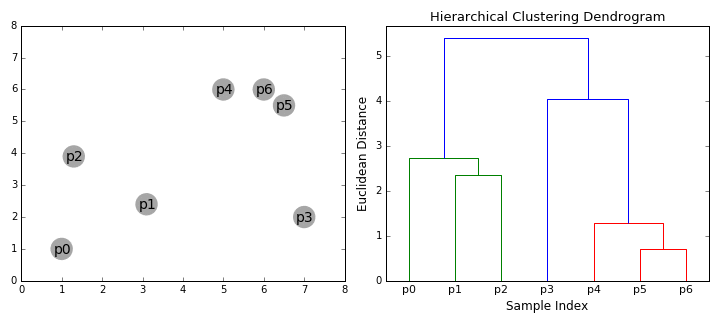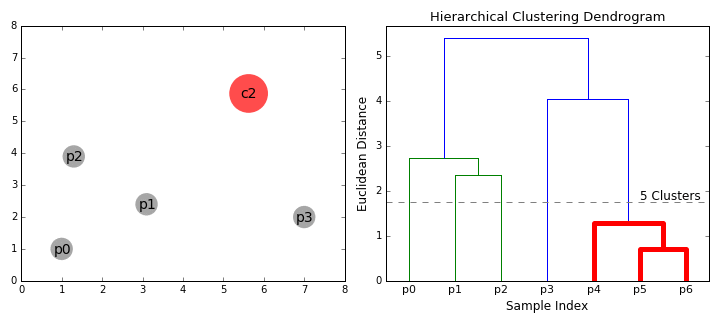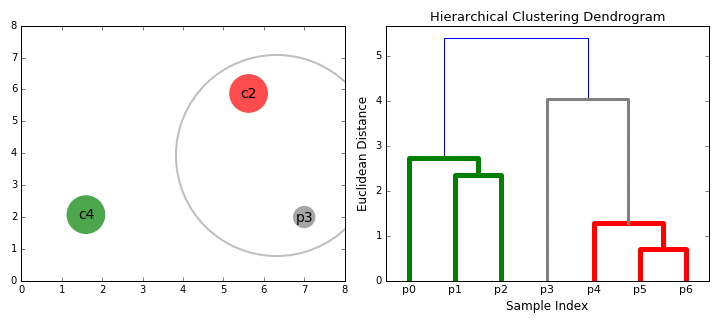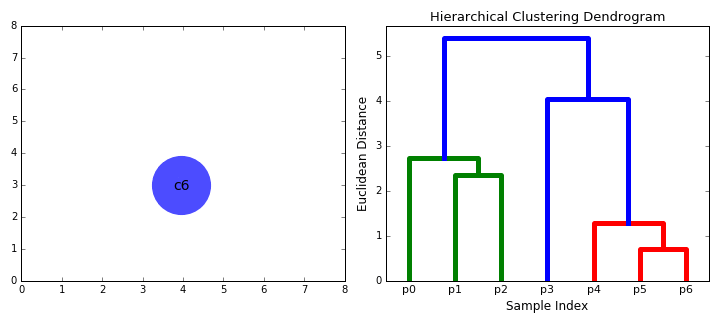
=== [[Hierarchical Clustering; Agglomerative (HAC) & Divisive (HDC)]] === | === [[Hierarchical Clustering; Agglomerative (HAC) & Divisive (HDC)]] === | ||
| − | + | https://cdn-images-1.medium.com/max/800/1*ET8kCcPpr893vNZFs8j4xg.gif | |
<youtube>Yn3VV9emiCs</youtube> | <youtube>Yn3VV9emiCs</youtube> | ||
Latest revision as of 07:38, 17 August 2023
- ...cluster
- If text only, then try...
- for text categories try K-Modes
- for discovering semantics and syntax try Natural Language Processing (NLP) algorithms such as Topic Model/Mapping
- If finding transaction data relationships, then try Association Rule Learning
- If you know how many groups/classes there are...
- Yes
- ...using numeric values to find categories, then try the K-Means algorithm
- ...need to be less sensitive to data scaling, then try Mixture Models; Gaussian
- No
- ...size of the clusters, then try the Mean-Shift Clustering algorithm
- ...size of the clusters may vary, then try the Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
- ...clusters aren't necessarily circular, and points are allowed to be in overlapping clusters, then try Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM)
- ...the distance metric shouldn't be key, then try Hierarchical Clustering; Agglomerative (HAC) & Divisive (HDC)
- ...finding categorical values, then K-Modes clustering
- Yes
- If text only, then try...
___________________________________________________
- Clustering
- Quick Cluster Analysis for Excel
- Excel ... Documents ... Database; Vector & Relational ... Graph ... LlamaIndex
- Choosing the Right Clustering Algorithm for your Dataset | josh Thompson - KDnuggets
- The 5 Clustering Algorithms Data Scientists Need to Know | George Seif - KDnuggets
- Machine Learning: Trying to discover structure in your data | Stacey Ronaghan - Medium
Given a set of data points, we can use a clustering algorithm to classify each data point into a specific group. In theory, data points that are in the same group should have similar properties and/or features, while data points in different groups should have highly dissimilar properties and/or features. Clustering is a method of unsupervised learning and is a common technique for statistical data analysis used in many fields. We can use clustering analysis to gain some valuable insights from our data by seeing what groups the data points fall into when we apply a clustering algorithm. The 5 Clustering Algorithms Data Scientists Need to Know
Contents
K-Means Clustering
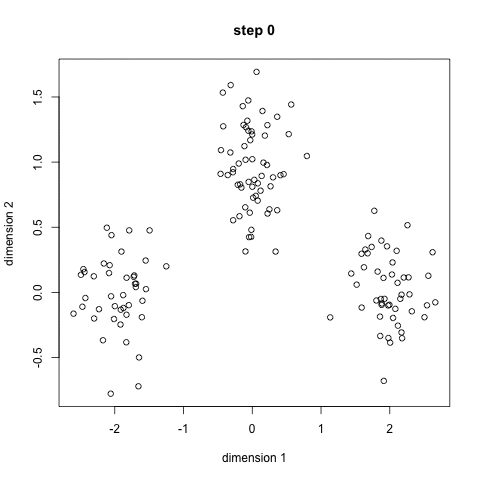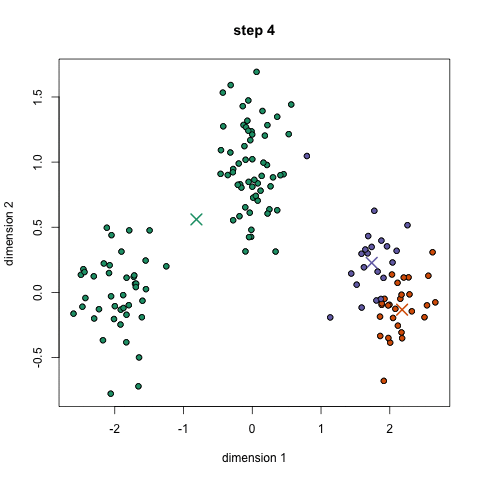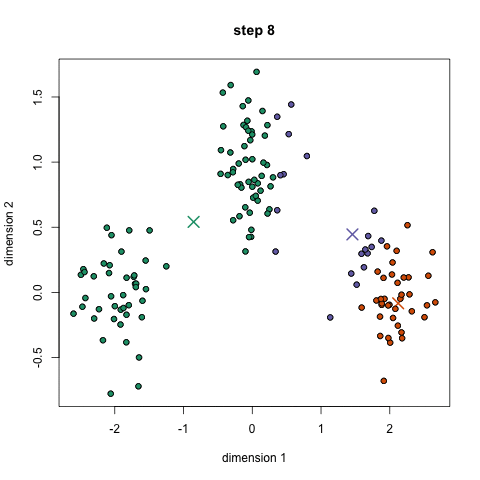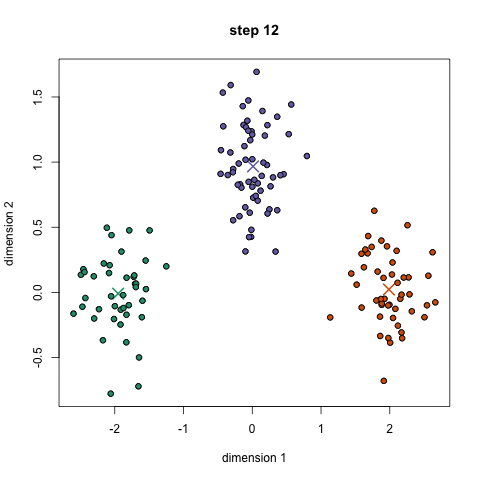
Mean-Shift Clustering

Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM)
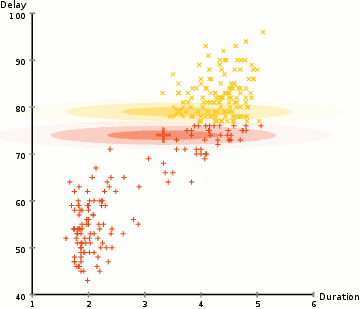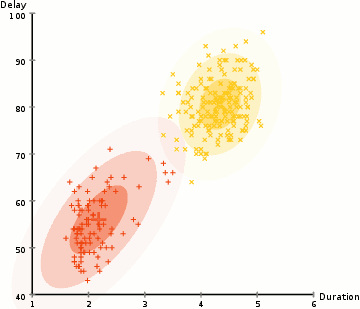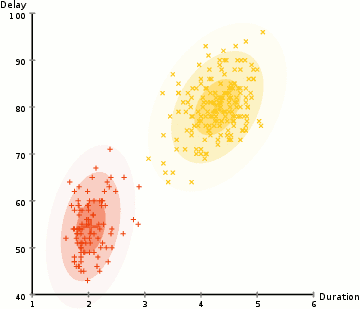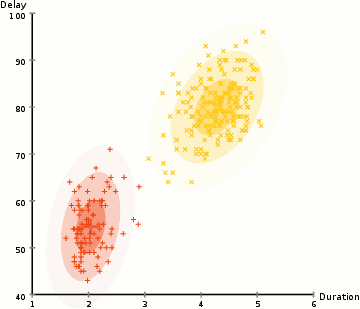
Hierarchical Clustering; Agglomerative (HAC) & Divisive (HDC)